What is partitioning?
Partitioning splits the data in a data structure into independent groups called partitions. This unlocks three key capabilities:- Partition skipping: When a computation targets specific partitions, Atoti scans only those partitions rather than the entire data structure.
- Parallel processing: Each partition is the base unit of parallelization. When all partitions are involved in a computation, they can be processed concurrently and their results consolidated. This requires partitions to be roughly equal in size.
- Faster writes: Because partitions are independent, multiple partitions can be written to simultaneously without contention.
- Disproportionate partitions: if one partition holds significantly more records than the others, all partitions will wait on that partition to complete. This can be observed during data loading as CPU usage briefly peaks near 100% before dropping to single digits while the remaining partition finishes loading.
- Too many partitions: if the partition count is an order of magnitude higher than the CPU count, query performance will degrade due to context switching.
What is NUMA awareness?
Note: NUMA awareness is only available on Linux servers.NUMA (Non-Uniform Memory Architecture) is a memory architecture used in multi-socket servers. Each CPU socket has its own local memory, and accessing local memory is faster than accessing memory on another socket. When threads read data from remote memory, latency increases and processing slows down. NUMA awareness builds directly on partitioning:
- Each partition is assigned to a specific NUMA node
- Threads operating on a partition are bound to the same node as the partition.
- Memory access is therefore local to the CPU socket and improves query performance.
- The placed policy (default) creates one thread pool per NUMA node. Each thread is bound to its node and performs memory allocation on that node. Data allocated on a node is bound to that node, and all read and write operations are performed by the associated thread pool. This maximizes data locality and minimizes latency.
- The free policy creates a single thread pool spanning the entire system. Threads are managed by the OS and can move between nodes at any time. No effort is made to maximize data locality.
Further reading:
Atoti Java SDK and Atoti Python SDK use the same set up for NUMA awareness and NUMA policiesWhat are the benefits of defining a partitioning strategy?
Atoti automatically defines a partitioning strategy for both stores and aggregate providers. This is a best-effort approximation and works for some use cases. In addition, defining an explicit partitioning strategy gives control over the following:- Multi-core performance: An even distribution of records across partitions ensures that all cores are kept busy during both loading and querying.
- Parallel query execution: Work is distributed across partitions, each processed by a separate thread, regardless of whether NUMA is involved.
- Data maintenance: Updating data is done by partition. For example: removing all records for a given date is done by removing an entire partition instantly rather than scanning all records.
- NUMA locality: Explicitly mapping partitions to NUMA nodes ensures that threads and their data stay physically co-located in memory, minimizing cross-node latency.
- Long-term stability: A deliberate partitioning design accounts for how data will grow and evolve, and reduces the risk of skewed partitions or excessive partition counts over time.
Which partitioning strategies does Atoti offer?
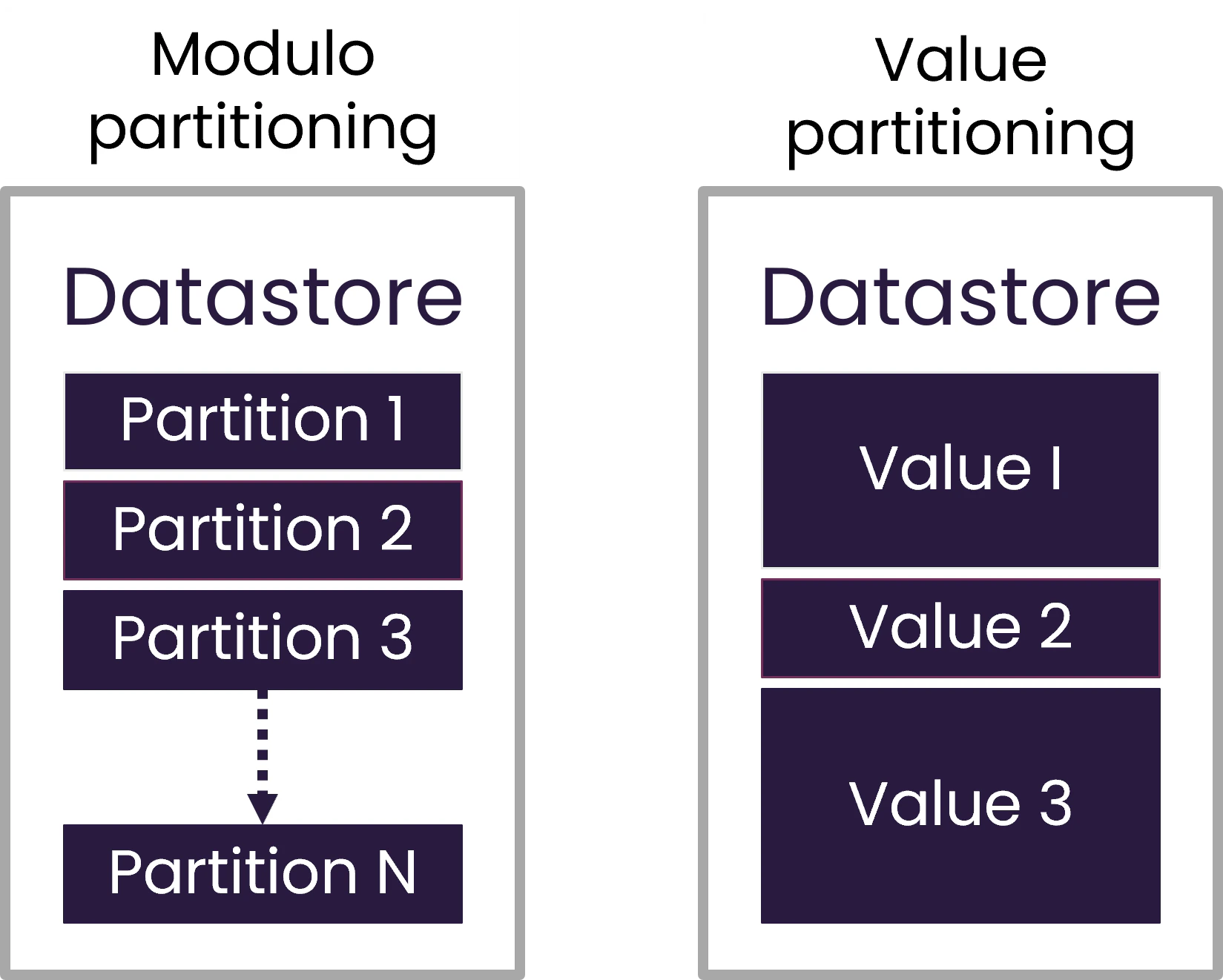
Modulo-based partitioning
- The number of partitions is determined upfront, usually based on the number of machine cores.
- Provides an even distribution of data values across partitions.
- Not optimal for housekeeping operations, as partitions are not aligned with specific data values.
Value-based partitioning
- Each unique value of a chosen field creates a partition.
- Partition size depends on the amount of data per value.
- Useful when loading data across multiple dates or categories.
- Not optimal when the field has high cardinality (many unique values).
Related reading
Which constraints affect partitioning?
Two constraints must be respected when configuring partitioning.- Key field constraints
- If a store has key fields, the partitioning fields must be included in those key fields.
- If a store has no key fields, it can be partitioned on any of its dictionarized fields.
- Store reference constraints
- When a store references to another store, the partitioning of the referenced store is implied by the partitioning of the owner store.
- All records in a given partition of the owner store must reference records in the same partition of the referenced store.
- As a result, the referenced store has a number of partitions that is less than or equal to the number of partitions in the owner store.
What is the optimal number of partitions?
Atoti recommends configuring at least one partition per logical core. Modern processors use hyper-threading, which provides two logical cores per physical core. For this reason, the recommended minimum is twice the number of physical cores. For NUMA-aware applications, the minimum requirement is one partition per physical processor. However, using one partition per logical core is preferred, as it reduces contention between concurrently running threads.When is custom aggregate provider partitioning needed?
By default, Atoti partitions aggregate providers to closely follow the datastore partitioning. This supports multithreaded performance at the cube level. There are two cases where overriding this may be necessary. The optimal partitioning field is not on the base store. Partitioning constraints require that partitioning fields belong to the base store or its key fields. If the field that would give the best distribution belongs to a referenced store, the base store cannot be partitioned on it directly. Defining a custom partitioning on the aggregate provider allows that field to be used at the cube level, independently of the store partitioning. Query patterns differ from loading patterns. A partitioning designed for efficient data loading may not distribute query work evenly across cores. For example, data is partitioned by date for faster loading, but queries consistently target a different dimension than the date dimension. A custom aggregate provider partitioning can better reflect those access patterns.Note: Customizing aggregate provider partitioning adds cost to the commit phase. Data may need to be scanned and re-routed to match the provider’s partition layout, increasing commit time and transient memory usage while committing.