Hybrid distributed mode
A classic use case for DirectQuery is giving access to the historical data of an in-memory Atoti application. Historical data may be too large to fit entirely in-memory or too costly for “cold” data that users rarely access. For that, it is possible to have Atoti DirectQuery nodes alongside Atoti in-memory nodes in a Distributed set-up and expose it in a unified and consistent data model to the end users.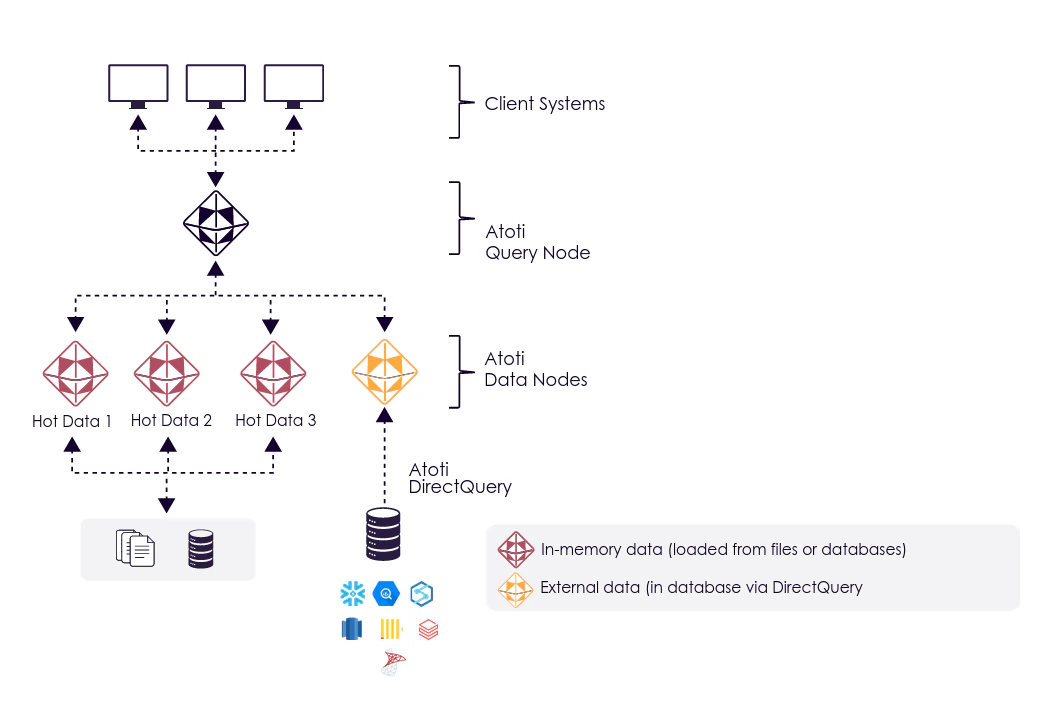
IDatabase interface, the same cube definitions (measures, hierarchies…) can be used for all the nodes.
A usual set-up to split “hot” and “cold” data is to use a date hierarchy:
- the recent dates are put in-memory because they will receive a lot of queries and might have frequent real-time updates.
- the older dates are put in an external data warehouse and accessed via DirectQuery because it accessed less frequently and receive rare updates. Part of this data can be pre-aggregated to provide an historical overview pretty quickly.
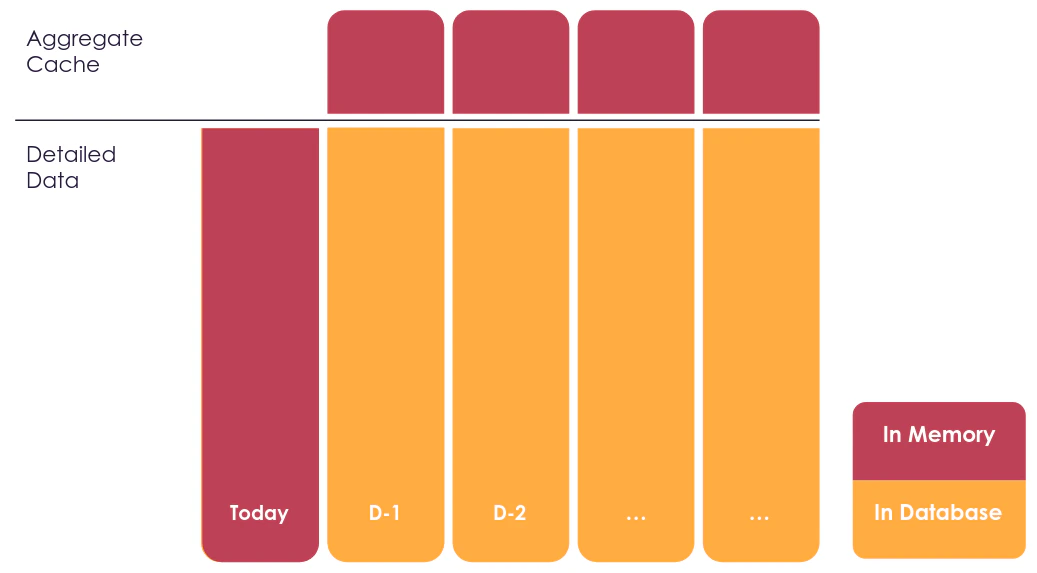
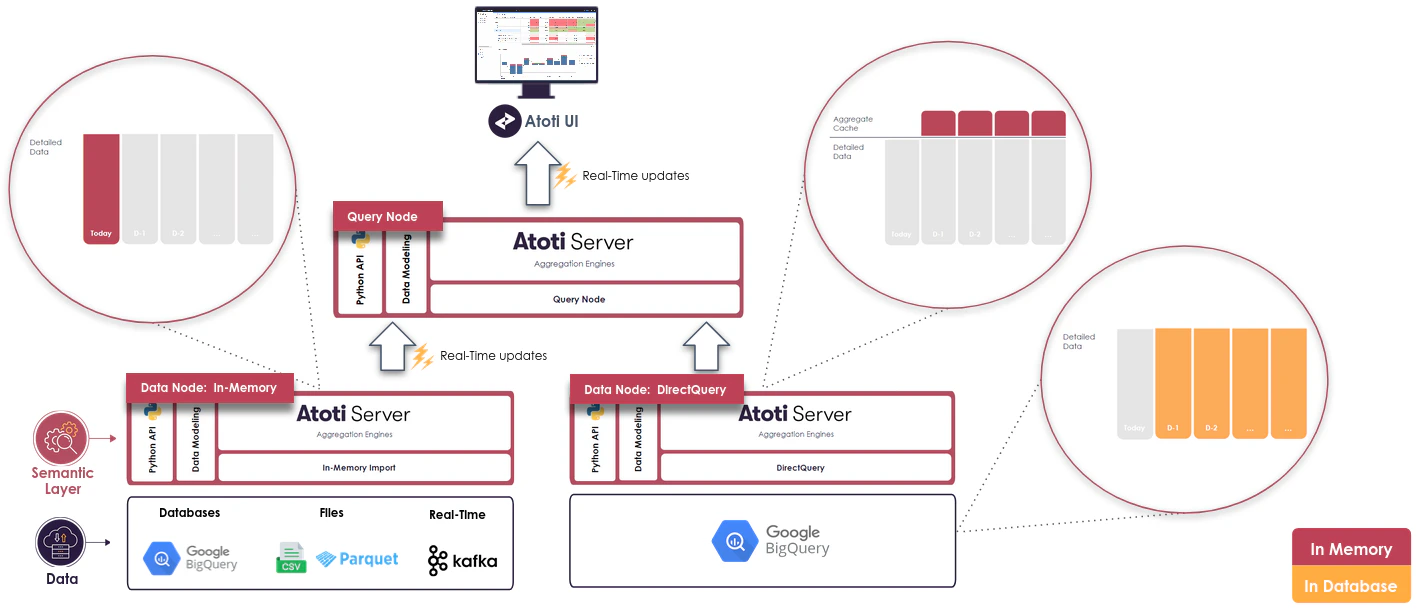
- The majority of queries will be on recent dates and hit the in-memory nodes
- Historical trends queries will hit the DirectQuery partial aggregate providers which are in-memory
- When users start to drill down on historical data, the queries will be sent to the external database but at this point there should be a scope filtered enough (1 book on 1 date for instance) for the warehouse to answer quickly.