Post-Processors
Introduction
ActivePivot introduced a while ago a key feature called Post-Processors, which provides the ability to evaluate business logic for each request to aggregated data. The Post-Processors were called such because they are computed after the basic aggregated measures. However, they must not be confused with the Transform phase of ETL (which happens when loading data in the datastore). Post-processors are in fact applied on-the-fly, only on relevant data, during a query.
Post-processors are defined on the server side with Java code. The Post-Processors are the "old way" to add your own business logic to the computations done in the ActivePivot engine. Since then, we introduced the Copper API, which is much easier to use. Post-processors are available for retro-compatibility and for complex use cases where the Copper API does not yet offer a satisfying alternative.
Post-Processors are extremely flexible and can use the following types of data to compute their results:
- Pre-aggregated data
- Custom aggregations
- Other post-processor results
- External resources (e.g. share prices, FOREX)
Most of the time the Post-Processor retrieves underlying measures at some location, performs additional computation with the (optional) help of some services deployed in the application, and writes its own output to the result cell set.
Post-Processors advantages include the following:
- The end user does not need to know if a measure is post-processed or just pre-aggregated data; everything is just a Measure.
- Post-Processors are written in Java. This allows you to use many external systems and provides more flexibility than MDX's calculated measures.
- Post-Processors offer infinite possibilities for computations. ActivePivot's post-processors can easily and and accurately compute the PnL of a trade, using real-time data streams (e.g. share prices and FOREX).
- The results of any Post-Processor can be computed across any dimension.
- Post-Processors are more flexible than traditional database-stored procedures.
- The results can depend on the query context (e.g. on the user).
Post-Processed Measures
Below are some common business cases that use post-processors:
- Simple arithmetic operations (e.g. calculating a ratio between levels)
- Currency conversions (e.g. using external data to convert a trade's currency to a common currency)
- Presentation effects (e.g. hiding meaningless values from users)
- Displays of market data (e.g. showing the market data used in a currency conversion)
- Running totals (e.g. showing how cash flows accumulate over a given time period)
- Computing non-aggregating values (e.g. VaR)
- Real-time market data updates (e.g. FX and P&L)
IPostProcessor
IPostProcessor is the base interface for all PostProcessors.
The compute method is responsible for implementing the actual business logic:
/**
* Main evaluation method of the post processor The post processor computes the aggregates within the scope of
* a range location, with the help of an aggregate retriever it can use to retrieve dependent aggregates.
* <p>
* The post processor can retrieve any kind of aggregate from the retriever, included aggregates that have been
* previously computed by another post processor. The query engine is in charge of arranging post processor
* chains accordingly.
* <p>
* The result of this post-processor evaluation should be written to the result using the given retriever.
*
* @param location The location to evaluate this post-processor for
* @param retriever The retriever that can provide underlying aggregated values
* @throws ActiveViamException if an exception occurs during this computation
*/
void compute(ILocation location, IAdvancedAggregatesRetriever retriever) throws ActiveViamException;
Note that the IPostProcessor is created only once per version of the cube and then shared between queries,
so you must be careful not to maintain state in instance variables.
Once created, the post-processor is initialized with its properties via the init method:
if several measures configured in the cube use the same post-processor plugin key with different properties,
one instance will be created for each measure.
Provided Post-Processors
ActivePivot's post-processors are in the activepivot-ext module. Source code is provided
there as an example for you to write your own.
Note that, most of the time, you won't need to use those post-processors since their logic is available through the Copper API, which is much simpler to use. All concrete implementations for the built-in post-processors have a Copper counterpart. You can, however, extend the abstract classes for additional flexibility to handle (and potentially optimize) specific use cases.
The following diagram illustrates the available post-processors:
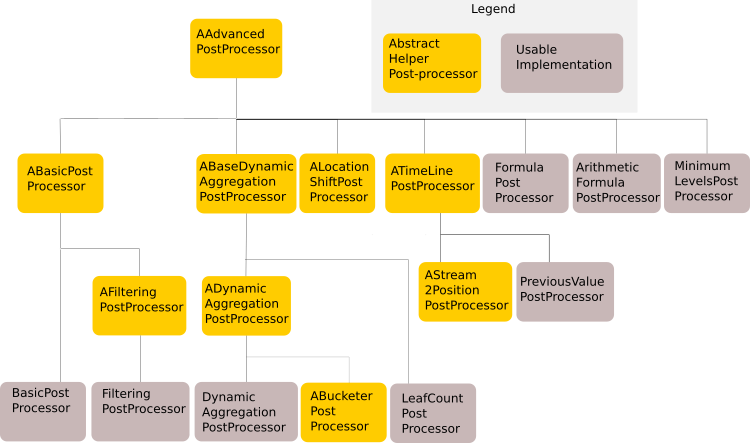
AAdvancedPostProcessor
This is the abstract base class for all post-processors.
When implementing a new post-processor, we recommend extending this class (or one of its existing subclasses) as it contains boiler plate code to retrieve underlying measures and to declare the context dependencies and continuous query handlers.
ABasicPostProcessor
This is an abstract base class for simple post-processors that retrieves its underlying aggregates at the same location for which it computes its result.
The ABasicPostProcessor allows a calculation to occur for each cell for which the user requests aggregates.
Unlike the ADynamicAggregationPostProcessor, no extra aggregation occurs on the calculated values.
This post-processor allows calculations and cosmetic changes to occur only on the cells requested.
Anything that is written as a function of underlying aggregates and external data can be modeled as an
ABasicPostProcessor. VaR is a common example, where the percentile needs to be retrieved from a vector for each cell
in a user's view. This can be combined with user preferences (context values),
to allow the user to choose the percentile or the method of calculating VaR (simple percentile, expected shortfall,
exponentially weighted expected shortfall), which will be used during the calculation.
ABasicPostProcessor implements IPartitionedPostProcessor and sets its partitioning levels
based on the wildcards in the location where it is computed, provided its partitionedOnRangeLevels property allows it
(or the default value set by ActiveViamProperty.DEFAULT_PARTITIONING_ON_RANGE_LEVELS_PROPERTY
if the specific property is not set for the post-processor).
ABasicPostProcessor also implements IEvaluator, so any concrete implementation can be used by other post-processors
that use an IEvaluator, such as the DynamicAggregationPostProcessor.
ABasicPostProcessor is the easiest abstract post-processor implementation to understand.
However, it can cover a multitude of business use cases.
The business logic should be implemented in the evaluate method:
/**
* This method is called to evaluate the post processor value on a given location.
*
* @param location This location is a point (non range) location
* @param underlyingMeasures The values of the defined underlying measures
* @return The post processor value
*/
@Override
public abstract OutputTypeT evaluate(ILocation location, Object[] underlyingMeasures);
BasicPostProcessor
This post-processor is a concrete implementation of the ABasicPostProcessor, which delegates its evaluation to an
IEvaluator. Its plugin key is "BASIC". When configuring the BasicPostProcessor, you must set its evaluator
property to the plugin key of the IEvaluator you want to use.
The use of an IEvaluator does not change what has to be implemented (the evaluate method signature is
the same in the BasicPostProcessor and in the IEvaluator). However, it allows for easier code reuse, since
the implementation of the IEvaluator can also be used for a DynamicAggregationPostProcessor.
BasicPostProcessorusage is deprecated as it is strongly recommended you use Copper API for defining simple measures instead. Using the Copper API allows for less verbose, more maintainable code, and enables a functional definition of the measures.
AFilteringPostProcessor
This abstract post-processor filters locations based on conditions on levels,
by editing the query filter during prefetch. The evaluation is based on an IEvaluator.
If there is no evaluator defined, but the post-processor has only one underlying measure,
it is assumed the post-processor filters that measures's value.
FilteringPostProcessor
This is a concrete implementation of AFilteringPostProcessor, which filters on specific members for given levels.
The plugin key for this post-processor is "FILTERING".
When configuring the FilteringPostProcessor, you must define the leafLevels property
(the levels where you define your filters) and the membersToFilterFor property (the member values for each leaf level).
The Copper counterpart to this post-processor is a filtered measure.
ABaseDynamicAggregationPostProcessor
This is an abstract post-processor with support for high performance dynamic aggregation. The concept of dynamic aggregation is explained in the ActivePivot Concepts in a Nutshell article.
ABaseDynamicAggregationPostProcessor is a dynamic aggregation post-processor that retrieves its underlying
aggregated values at the requested leaf levels and reduces them to the requested scope.
It can be parameterized by defining the leafLevels property (the level to which it should go to for prefetching data
and applying a transformation procedure) and the aggregationFunction property
(the plugin key of the reduction aggregation function).
The transformation procedure applied at the leaf level should
be defined by implementing the createLeafEvaluationProcedure method:
/**
* Create the {@link ITransformProcedure transformation} procedure that will be executed on the underlying
* {@link IIterableAggregatesRetrievalResult result at the leaf level} and that will return the actual leaves.
* <p>
* Sub-classes can override this method to return their own procedure implementation.
*
* @param result The result containing the underlying values
* @param measureIds The IDs of the underlying measures in the result
* @return The procedure used to transform the result
*/
protected abstract ITransformProcedure createLeafEvaluationProcedure(
final IIterableAggregatesRetrievalResult result,
final int[] measureIds);
ABaseDynamicAggregationPostProcessor implements IPartitionedPostProcessor. The partitioning levels are set as the
leaf levels or their parents.
ADynamicAggregationPostProcessor
This class provides a leaf evaluation procedure at one less level of abstraction than the
ABaseDynamicAggregationPostProcessor so that you only need to implement evaluateLeaf:
/**
* Perform the evaluation of the post processor on a leaf (as defined in the properties).
*
* @param leafLocation The leaf location
* @param underlyingMeasures Values of the underlying measures for the leafLocation
* @return The leaf result
*/
protected abstract LeafType evaluateLeaf(ILocation leafLocation, Object[] underlyingMeasures);
DynamicAggregationPostProcessor
This is a concrete implementation of a dynamic aggregation post-processor that delegates its leaf evaluation to an IEvaluator.
The plugin key for this post-processor is "DYNAMIC".
The Copper counterpart to this post-processor is a dynamic aggregation measure.
ABucketerPostProcessor
This post-processor is used to perform bucketing, e.g. aggregating the underlying metrics on a specific bucket hierarchy by following a user-defined logic.
For instance, if you have a Maturity Date, the indicator can be displayed as something more collective and less granular than a date, such as:
- 1W
- 1M
- 1Y
Configure this through two properties:
-bucketHierarchy is the hierarchy where the buckets are (e.g. 1W, 1M...)
-bucketedLevel represents the level to bucket (e.g. the dates).
The bucketing logic must be implemented in the getBucket method:
/**
* Retrieve the bucket the entry belongs to. This method is dynamically called by the post processor while it
* aggregates data into the buckets.
* <p>
* During the typical evaluation of a post processor, this method may be called a large number of times. As
* bucket selection is in general a costly operation involving sorting, it is recommended that the query cache
* is used to store intermediary structures to accelerate the bucket selection algorithm.
*
* @param entry A coordinate on the bucketed level
* @return the selected bucket
*/
public abstract Object getBucket(Object entry);
The Copper counterpart to this post-processor is a bucketing hierarchy.
LeafCountPostProcessor
This is a dynamic aggregation post-processor that counts the number of leaves that contribute to the aggregate for each queried aggregate. Configure the depth of the leaves in the same way as for dynamic aggregation post-processors.
This post-processor is a concrete implementation, with the plugin key "LEAF_COUNT".
LeafCountPostProcessor is used to compile the DistinctCount from MDX queries.
Altering its behavior might make the results of the DistinctCount formula differ from the MDX specification.
ALocationShiftPostProcessor
This post-processor allows data to be read from one location
and written to the location specified in the query.
This is done by overriding the shiftLocation method:
/**
* Shift the evaluation location into the read location.
* <p>
* This method is used to shift the input evaluated location to retrieve the result set from which the returned
* values will be read.
* <p>
* This method can return {@code null} to skip the evaluation of the post processor on the specified location.
*
* @param evaluationLocation A location at which the post processor is evaluated
* @return the read location at which the post processor will actually read the underlying aggregates from
* which it will derive the result associated with the evaluation location
*/
protected abstract ILocation shiftLocation(ILocation evaluationLocation);
This allows post-processors to be chained together for performing calculations using measures for different locations.
It does this by attaching those measures to locations that other post-processors can use. The most common example is
calculating the difference between two days, where the implementation of the ALocationShiftPostProcessor shifts
the location to retrieve data for 'Yesterday'.
The Copper counterpart to this post-processor is a location shifting measure.
ATimeLinePostProcessor
This post-processor builds its query evaluation by applying logic on the different values of a measure along a time hierarchy.
This post-processor is configured by providing several properties:
timeHierarchyName: the time hierarchy upon which we are operating,streamMeasureName: the measure that is considered as a "stream" along the time hierarchy,positionType: how we depend on the stream measure along the time hierarchy. In fact, the post-processor can depend on the current value or not :- previous values, including the current one (positionType = "CURRENT_STREAM")
- previous values, excluding the current one (positionType = "PREVIOUS_STREAM")
The available methods allow you to choose the locations along the time hierarchy you are interested in, along with how to aggregate the measure on those locations:
/**
* @return The value before considering the first cell of the timeline
*/
protected abstract OutputType getInitialPosition();
/**
* @param previousPosition Value on the previous element of the timeline. It may be mutated
* @param currentValue value of the underlying measure on the current cell of the time line
* @return the aggregation of current cell with previous position
*/
protected abstract OutputType aggregateNextEntry(OutputType previousPosition, Object currentValue);
@Override
public abstract Object[] computeRequiredLocations(
ILocation location,
Collection<Object[]> rangeLocationArrays,
Collection<ILocation> locations);
For continuous queries, this post-processor uses TimeLineHandler to calculate its impact
(the only core implementation of handler that depends on its measure, since the handler needs to know which hierarchy
is the time hierarchy that the measure is interested in).
The Copper counterpart to this post-processor is an analytic function.
AStream2PositionPostProcessor
This post-processor is an abstract implementation of the ATimeLinePostProcessor that specializes in computing the cumulative aggregation of a measure along the time hierarchy.
Simple applications include calculating the cumulative sum of a measure over time,
or computing the minimal value reached so far for a measure.
The Copper counterpart to this post-processor is an aggregate analytic function.
PreviousValuePostProcessor
This post-processor is a concrete implementation of the ATimeLinePostProcessor, which,
given a cell and a time hierarchy, returns the ATimeLinePostProcessor underlying the time hierarchy.
Its plugin key is "PreviousValue".
The Copper counterpart to this post-processor is the
lagnavigation analytic function.
FormulaPostProcessor
This post-processor applies an IFormula defined in its initialization properties.
It is a concrete implementation, with the plugin key "FORMULA".
The formula is written in Reverse Polish Notation, with operators specified after their operands.
The operands are extended plugins of the IOperand interface.
It means that you can extend the set of operands by adding new IOperand extended plugin values.
The built-in operands are:
| Operand | Description | Example |
|---|---|---|
| double | Creates a specific double value | double[1.5] |
| float | Creates a specific float value | float [1] |
| int | Creates a specific integer value | int[1] |
| long | Creates a specific long value | long[1] |
| string | Creates a specific string value | string[example] |
| null | Always evaluated to null | null[] |
| aggregatedValue | Fetches a measure on the current location | aggregatedValue[pnl.SUM] |
| parentAggregatedValue | Fetches a measure on the parent node of the current location | parentAggregatedValue[pnl.SUM::Underlyings@Underlyings]Evaluates the measure pnl.SUM for the parent location on hierarchy Underlyings of the evaluated location |
| childAggregatedValues | Fetches a measure for all children of the current location | childAggregatedValues[delta.SUM::Underlyings::true]Evaluates pnl.SUM on the children relative to hierarchy Underlyings of the evaluated location, and returns a sorted list of the results. |
| levelValue | The name of the member at the given level, or null | levelValue[BookId@Desk@Booking]Returns the id of the book of the location being evaluated, or null if the location is not deep enough |
| dynamicAggregation | Re-aggregates the result from the leaf levels on the given hierarchy using the given aggregation function | dynamicAggregation[Currency@Underlyings::delta.SUM::AVG]Expands the evaluated location on the level Currency of the Underlyings hierarchy, and aggregates all the delta.SUM results using the AVG aggregation function |
The operators are plugins of the IOperator interface.
This means that the set of operators can be extended by adding new IOperator plugin values.
The built-in operators are:
| Operator | Description |
|---|---|
| + | Sums of all previous elements |
| - | Substracts the last value from the penultimate value |
| CONCAT | Concatenates (as in string) all previous elements |
| / | Divides the penultimate value by the last value |
| * | Multiplies all previous elements |
| SUBVECTOR | Creates a subvector of a vector: operands are the vector, the included from index, the excluded to index |
| div | Ternary divide operator: numerator, denominator, and an optional third argument that is the value to return when the numerator is not null, and the denominator is null or 0 |
The FormulaPostProcessor supports grouping operations through the usage of brackets.
You can define a sub-formula inside another formula by setting an entire formula between brackets.
Sub-formula evaluation will precede the surrounding formula evaluation.
Example: (int[4], int[5], *), (int[3], int[2], +), - <=> (5 × 4) - (3 + 2) <=> 15
This post-processor can be replaced by combining various measures and operations through the Copper API.
The FormulaPostProcessor is evaluated only for the locations where contributors.Count is > 0.
So, if you use operands that are post-processed measures that produce values even for locations
where the contributors count is 0 (such as a PreviousValuePostProcessor, for example),
you might end up with a null result for your formula even if the operands are not null.
To overcome this behavior, there is an alternative core post-processor, called
ArithmeticFormulaPostProcessor.
ArithmeticFormulaPostProcessor
Like the FormulaPostProcessor, the ArithmeticFormulaPostProcessor applies an IFormula defined in its
initialization properties. However, that formula is an ArithmeticFormula, e.g. it only allows the
double, float, int, long, null and aggregateValue operands, and only allows + , -, * , / and div
operators.
This post-processor is a concrete implementation, with the plugin key "ARITHMETIC_FORMULA".
Contrary to the FormulaPostProcessor, the ArithmeticFormulaPostProcessor is evaluated where the measures defined
in the formula as aggregatedValue are not null (instead of where contributors.COUNT is >0).
The Copper counterpart to this post-processor is an arithmetic operation.
MinimumLevelsPostProcessor
This post-processor hides underlying measures when the queried locations are higher than some given levels in their respective hierarchies. In some use cases the aggregation of base data above a given level does not make sense; for instance, summing amounts in different currencies, or summing data from different historical dates.
This post-processor is a concrete implementation, with the plugin key "MINIMUM_LEVELS".
The Copper counterpart to this post-processor is the
doNotAggregateAbovemethod.
Special Post-Processor Interfaces For Evaluation Performances
IPartitionedPostProcessor
The IPartitionedPostProcessor allows you to split a partitioned post-processor computation across multiple
partitions. Results from each partition are then reduced back into a final result.
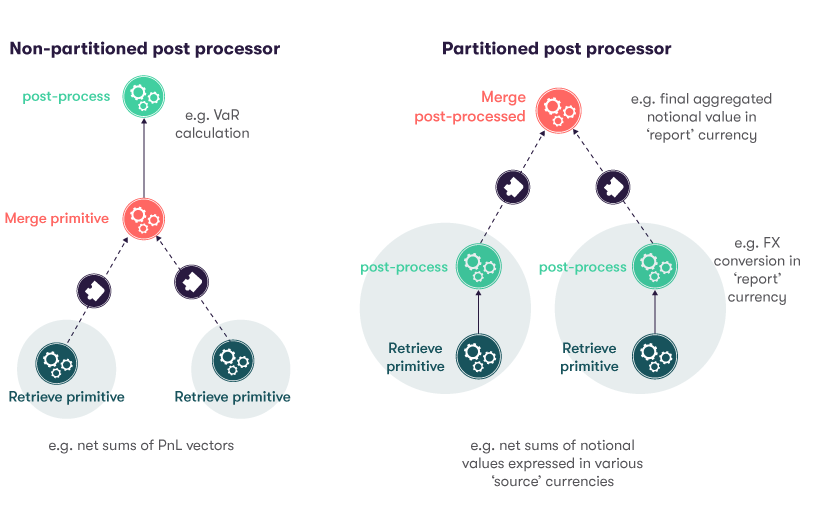
This allows for better performance over waiting for all underlying measures from all partitions to be available before computing the post-processor's results.
Implement the reduce method to define how each partition's results are reduced into a final result:
/**
* Reduces the partial {@link IAggregatesRetrievalResult results} of the execution of this post-processor on
* each partition into a global result and contributes it to the {@link IPostProcessedRetrievalResultWriter
* writer}.
*
* @param location The location on which this post-processor is being executed
* @param partialResults The results of the execution of this post-processor on each partition
* @param writer The writer to contribute to
*/
void reduce(
ILocation location,
List<IAggregatesRetrievalResult> partialResults,
IPostProcessedRetrievalResultWriter writer);
Then override the setPartitioningLevels method
(defaulted to doing nothing in parent IPostProcessor interface).
@Override
default void setPartitioningLevels(ILocation location, Collection<ILevelInfo> partitioningLevels) {
throw new UnsupportedOperationException(
IPartitionedPostProcessor.class.getSimpleName()
+ " must define the levels on which they partition.");
}
IDistributedPostProcessor
The IDistributedPostProcessor is a distributed, partitioned post-processor that may be distributed on each data cube,
regardless of its partitioning levels.
/**
* Returns whether this post-processor evaluation can be partitioned on all the remote data cubes when executed
* on a distributed query {@link IDistributedActivePivotVersion cube}.
* <p>
* This method will be called before {@link #setPartitioningLevels} when this post-processor is executed on a
* distributed query cube.
* <ul>
* <li>If it returns {@code true}, this post-processor will be evaluated locally on each remote data cube, and
* all the partial results will be reduced using the {@link #reduce} method.
* <li>If it returns {@code false}, the {@link #setPartitioningLevels} method will be called as usual to decide
* whether this post-processor can be partitioned and executed locally on each data cube.
* </ul>
*
* @param location The location for which this post-processor will be evaluated
* @return {@code true} if this post-processor computation can be distributed for this location, {@code false}
* otherwise
*/
boolean canBeDistributed(ILocation location);
More information on distributed post-processors can be found in the Distributed Architecture section of the documentation.
ILinearPostProcessor
The ILinearPostProcesor is a linear post-processor that allows results to be aggregated linearly.
The result of a post-processor applied on a 'big' aggregate will be the same as when you
aggregate the outputs of a post-processor on each element of any partition of the 'big' aggregates.
For example, a basic post-processor that multiplies an underlying measure by 2 will give the same results if it is applied on a grand total, or if we sum its results on any partition of that total.
Implementing this interface lets the query engine know that it can deduce results for that post-processor from less aggregated results using the given aggregation function (this functionality is called "range sharing").