ETL for IMA Overview
As part of the data loading process, the ETL layer handles data manipulation between the file format and the internal datastore structure. For the various files, this can include:
- Vectorization
- Interpolation
- Normalization
These processes are performed through Column Calculator, Tuple Publisher and Publisher objects.
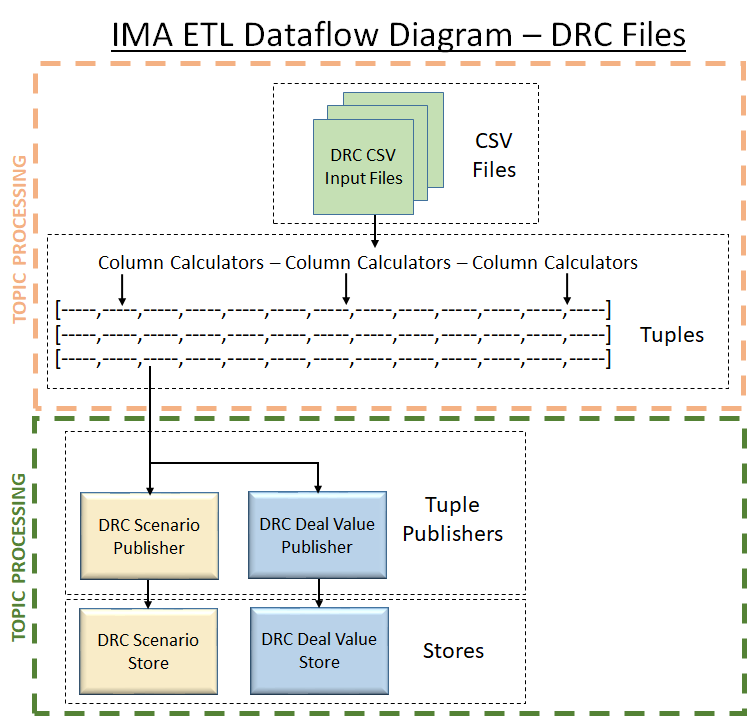
This section provides an overview of IMA ETL, starting with a dataflow diagram for DRC.
For information on specific ETL processes applied to individual CSV file types, see IMA ETL for DRC.
Dataflow Diagram
| DRC |
|---|
 |
Vectorization
This is fairly common in ActiveViam projects. It involves taking single values on multiple rows of the CSV file and combining them into a Vector to save space in the datastore. Combined with native vector aggregation, this provides better memory usage and aggregation speed and significantly decreases data duplication.
note
- The input of both vectorised and non-vectorised input data (and even a combination of the two) is supported. All values, individual or sub-vectors, are taken as input for the final vector representation of a sensitivity. An exception is made for vectors considered “pre-interpolated” (for details, see Pre-interpolated vectors).
- The vectorization is limited to a single file, and the csv source is configured to load an entire file into memory before attempting to vectorise. The csv source cannot be configured to perform vectorization across files.
Interpolation
Pre-interpolated vectors
If a row in a file contains a value without a set of corresponding input vertices (one or more, the number being equal to the number of input values), we assume the row to be “pre-interpolated” onto the FRTB vertices. This will bypass both vectorization and interpolation, and commit the input values to the datastore without any modifications. This aims to speed up the data loading by removing redundant operations.
note
Interpolation
This will change going forward. Because the set of vertices can change with jurisdiction, there will eventually be a need to move this interpolation to query time.
Normalization
Database normalization, or simply normalization, is the process of restructuring a relational database in accordance with a series of so-called normal forms in order to reduce data redundancy and improve data integrity.
Column Calculators
Column calculators are used to fill in fields that don’t have values in the store, and to define the available fields in a row loaded from a file without depending on the datastore setup.
Tuple Publishers
The tuple publishers used here link the collections of rows to the base store and to publishers handling other stores, sending only the relevant fields in the row.
- Normalization
The publishers perform the vectorization and interpolation required by
individual risk classes and measures, using the PublisherUtils utility
class.