Distributed Data Roll Over
The distributed data roll over feature means that data can be moved from one cube to another seamlessly.
A classic use-case is to partition data cubes by time. For example, the most recent dates are into an in-memory cube, while other historical dates are in an external database with a DirectQuery cube. With such design comes the need to move the data corresponding to the oldest dates from the in-memory cube to the DirectQuery cube, so we free some memory for the next dates.
In addition, it is also possible to temporarily load a datastore data node for some historical date for a quick analysis.
How to
With data overlap (recommended)
We recommend using data overlap to roll over distributed data seamlessly.
Data overlap makes it possible to maintain a version of the data available at all times, so there is no inconsistency in query results. In addition, there is no need to restart cubes, the query node will discover data nodes as they are started.
Example: date roll over
In order to free memory for the new date 104, the data for date 101 needs to be transferred from the in-memory cube to the DirectQuery cube:
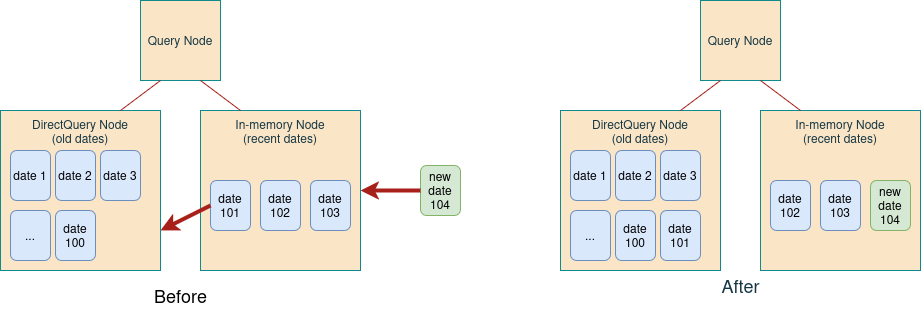
With data overlap enabled, the workflow is:
- Create the Date 101 node in DirectQuery
- Delete the Date 101 node in the datastore
- Create the Date 104 node in the datastore
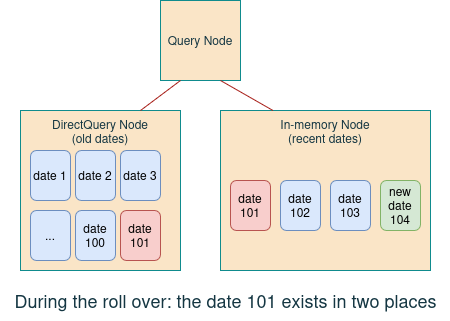
The duplicated data exists and is visible by the query node in both data nodes (the datastore one and the DirectQuery one), so query results remain consistent during the transition.
With the data overlap, we can even improve this workflow be having all the dates in DirectQuery. The workflow becomes:
- Delete the Date 101 node in the datastore
- Create the Date 104 node in the datastore
All nodes can share the same data source.
Handling consistent member removal
For a detailed guide on how to safely remove data in a distributed setup with data overlap, see the Remove data in overlap configuration page.
Without data overlap
If it is not possible to enable data overlap, a solution is to programmatically disable the queries on the query cube during the roll-over. We first delete the data from the in-memory cube, then insert it into the DirectQuery cube, and finally re-enable the queries on the query cube. The data is temporary in neither cube, but the queries are not executed during this time so the users do not see any inconsistency.
Example
One way to block the query is to use the experimental feature QueryBlockerUtil to reject all queries and to unregister
all the queries from the cube.
In this example, we implement a Spring controller which allows disabling and re-enabling the queries on the cube.
@RestController
@RequestMapping("/access")
public class AccessController {
private final IActivePivotManager manager;
@Autowired
public AccessController(final IActivePivotManager apManager) {
this.manager = apManager;
}
@GetMapping("/enable")
public String enableQueries() {
QueryBlockerUtil.allowQueries(this.manager);
return "Access is now enabled.";
}
@GetMapping("/disable")
public String disableQueries() {
QueryBlockerUtil.blockQueries(this.manager);
return "Access is now disabled.";
}
}
QueryBlockerUtil is an experimental feature and is subject to change in future releases. It requires the feature flag
activeviam.feature.experimental.query_blocker.enabled to be set to true.
Keep in mind the following limitations:
- The cube will be un-usable for a short period of time
- The same date cannot be present in several data cubes at the same time
Workflow
To be optimal, the roll-over workflow must minimize the time when the queries are not available. Here is an example workflow with an external database supporting time travel:
- Insert the data of the rolled date in the external database but do not trigger incremental refresh. This data is not used yet as the DirectQuery node uses a previous version of the data with Time Travel.
- Block the queries
- Remove the rolled date from the in-memory cube
- Run an incremental refresh on the DirectQuery node to add the rolled date
- Unblock the queries
- Add the new date in the in-memory cube