Distributed Architecture Overview
ActivePivot leverages multi-core CPU architectures extremely efficiently. The performance obtained from server CPUs with a large number of cores and large amounts of memory available to the JVM, together with the capability to swap part of the memory on disk, has allowed ActivePivot to successfully deliver outstanding performance to almost all business cases of its client base.
However, some use cases may benefit from having an architecture that supports multiple servers, spread across a local area network or a wide area network to deliver accrued performance and improve resilience.
ActivePivot can run as a distributed cluster on many machines. On each node of the cluster, two kinds of cubes can be run:
- Data nodes, which contain data cubes
- Query nodes, which contain query cubes
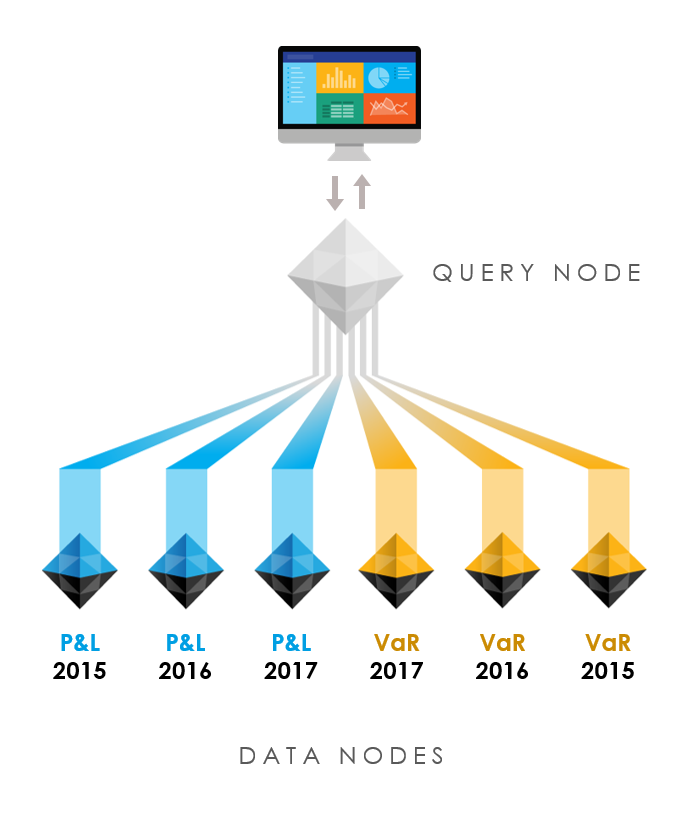
Query cubes
Query cubes offer a view of the cluster to the UI, and are the only ones that can receive queries across the entire cluster.
A query cube does not store any data in its datastore: when queried, it forwards the query to all data cubes in the cluster, performs the final steps of aggregation/post-processing, and returns the result to the user.
To be able to perform queries, a query cube does store one thing: the global cluster hierarchies, that is, all the members of all the hierarchies of all the data cubes. This means that the query cube's topology represents a merger of the topologies of all the corresponding data cubes.
For details about query execution and cluster creation, see the Communication flow topic.
Data cubes
Data cubes are the ones storing the data: their datastore is full of facts.
They also define their own hierarchies over those facts, and their own measures. So the data cubes
in a cluster can be very different from each other, as long as the query cubes are aware of the
differences.
Applications
A query cube does not merge any data cubes together, as they can be vastly different from each-other: the data cubes are grouped together through applications.
Within an application, the data cubes must have the same topology: the same hierarchies, the same levels, and the same measures.
Once the data cubes have been grouped at the application level, the query cube can group applications together and offer a view of the different applications in the cluster.
Two different applications cannot share the same measures.
Scalability
All data cubes that belong to the same application can share the same measure definitions, and their underlying data will be aggregated together. This corresponds to the idea of horizontal scaling.
Data cubes that belong to different applications MUST NOT share any measure definitions (except for the native contributors.COUNT and update.TIMESTAMP). By splitting strictly disjoint measures, and their associated data across multiple servers, it is possible to achieve a polymorphic distribution.
Polymorphic distributions are useful when measures do not apply across all dimensions. In this case, you can split the dimensions into smaller cubes, each with its own consistency, while keeping a comprehensive view of all available data within the query cubes, which are aware of the different applications.
It is therefore possible to have a combination of polymorphic and horizontal distributions within the same cluster using the application abstraction.
This is achieved in the Query Cube builders by specifying several applications, each with its own
distributing fields (see below).
When receiving the contributions to the Query Cube's hierarchies from a specific data node, we try
to merge dimensions, hierarchies and levels when they have the same unique name (the unique name is
the path to a specific level: for instance, the levelYear's unique name could look like
[TimeDimension].[TimeHierarchy].[Year]). This should feel natural to the end user.
Two hierarchies with the same name, but in different dimensions, will never be merged.
If Application1 has more levels in a specific hierarchy than Application2, the levels that can be merged will be, and the remaining levels will only appear for Application1.
For instance, three data nodes from a P&L application, distributed along a year field, and three data nodes from a VaR application, distributed along a year field, cohabit in the same cluster and can be queried from one query node.
For tips on configuration, see Recommendations.
Distributing fields
Distributing fields partition the data within a cluster. Here is a definition example:
return StartBuilding.cube(CUBE_NAME)
.withContributorsCount()
.withinFolder("Native_measures")
.withAlias("Distributed_Count")
.withFormatter(INT_FORMATTER)
.withUpdateTimestamp()
.withinFolder(NATIVE_MEASURES)
.withAlias("Distributed_Timestamp")
.withFormatter(TIMESTAMP_FORMATTER)
.asQueryCube()
.withClusterDefinition()
.withClusterId(CLUSTER_ID)
.withMessengerDefinition()
.withProtocolPath("jgroups-protocols/protocol-tcp.xml")
.end()
.withApplication(APPLICATION_ID)
.withDistributingFields("AsOfDate")
.end()
JGroups
In the previous example, we defined the configuration of a messenger (see withMessengerDefinition).
Each cube, whether it is a data or a query cube, comes with its own messenger.
A messenger allows for the discovery of the different members of the cluster, so that the cubes can interact with each other. It also keeps an up to date list of members within a cluster. When a machine is turned off, it is removed from the cluster.
For messengers to work, ActivePivot relies on JGroups for membership detection and join/left/shutdown cluster nodes notifications.
We provide two JGroups configuration files in the ActivePivot Sandbox. Both are only intended for development purposes with all cubes running on the same server/computer, and are not fit for production.
The production configurations highly depend on the cubes' locations and should be modified accordingly.