Distributed Architecture Communication Flows
Distributed Messenger
The distributed messenger is the component used to communicate between all the data and query nodes within a cluster. It allows for the discovery of different members of the cluster, so that the different nodes can talk to each other. It also keeps an uptodate list of cluster members, to prevent communication with disconnected members.
All nodes within the same cluster must use the same messenger type. ActivePivot relies on the following two types of messengers:
LocalMessenger
The LocalMessenger is an extremely efficient, pointer-passing message framework that avoids serialization
and other expensive operations when all the members of the cluster reside in the same JVM.
NettyMessenger
Netty is a lightweight asynchronous event-driven network application framework for high performance protocol servers & clients.
The NettyMessenger relies on this framework to acheive point-to-point communication between cluster members over TCP.
It is the default chosen messenger in ActivePivot.
The Netty messenger uses JGroups for member discovery and group membership.
JGroups
JGroups is a reliable multicast system that adds a "grouping" layer over a transport protocol. It provides the underlying group communication support for ActivePivot Distribution allowing members of a cluster to seamlessly discover each other using UDP multicast, or using TCP with additional setup.
A distributed node requiring group communication with remote node(s) will obtain a JGroups Channel to use for its communication with cluster members. The characteristics of a JGroups Channel are described by the set of protocols that compose it where each protocol handles a single aspect of the overall group communication task (Membership, Transport, Failure, Compression, etc). You can learn more about protocol configuration on the JGroups website: JGroups Advanced Concepts, JGroups Protocols List and JGroups Services.
JGroups configuration section can be found here: Jgroups Configuration.
In the following sections, referring to message exchange or message properties means a Netty messenger.
Message Types
There are two main categories of messages flowing in a distributed cluster: request messages and response messages.
Request Messages
Request messages are messages initiating a two-way communication between data nodes and query nodes. They can be broadcasted by either type of node depending on the purpose of the message. In that sense, request messages can be classified as follows:
Messages sent by query nodes to data nodes
| Type | Description |
|---|---|
| RetrieveAggregatesMessage | Messages sent by the query node to forward GetAggregatesQuery queries to data nodes. |
| DrillThroughHeadersMessage, InternalDrithroughHeadersMessage and DrillthroughMessageWithHeaders | Messages sent by the query node to forward DrillthroughQuery queries to data nodes. A DrillthroughQuery consists of several sub-queries, resulting in several exchange of messages between the query node and the underlying data nodes. |
Messages sent by data cubes to query cubes
| Type | Description |
|---|---|
| HelloMessage | Simple "hello messages" sent from data nodes to a query node within the cluster to make sure they can communicate with each other. |
| GoodbyeMessage | Simple "goodbye message" sent from a data node to a query node within the cluster to notify the latter that the former is leaving the cluster. |
| IInitialDiscoveryMessage | Messages sent by data nodes to each query node in the cluster. They enclose a serialized version of their entire hierarchies: the measure hierarchy with aggregate measures, post processed measures, plus all other member hierarchies. Once received and de-serialized by the query cube, these hierarchies are merged into the query cube's own hierarchies, creating new ones if necessary. |
| ITransactionCommittedMessage | Messages sent to notify the query node that a transaction happened on data nodes resulting in members update. The query node updates its hierarchies to reflect the members that have been added or removed as a result of the transaction. |
Response Messages
Response messages are messages sent as responses to request messages. They are in the form of BroadcastResult messages that can effectively wrap different types of response. These wrapped answers can be classified as follows:
Answers sent by query cubes to data cubes
| Type | Description |
|---|---|
| HelloMessageAnswer | Answers sent by a query node to a data node as a response to HelloMessage messages. |
| Null | BroadcastResult response messages sent by a query node to a data node as a response to IInitialDiscoveryMessage, ITransactionCommittedMessage and GoodbyeMessage messages. They have Null answers. |
Answers sent by data cubes to query cubes
| Type | Description |
|---|---|
| ScopedAggregatesRetrievalResultTransporter | Answers sent by data nodes to a query node as a response to GetAggregatesQuery queries. They represent the result of a single GAQ (GetAggregatesQuery) requested through a RetrieveAggregatesMessage request. This type of message holds the list of locations and the retrieval results for the subsequent GAQ. |
| DrillthroughHeader | Answers sent by data nodes to a query node as a response to a DrillthroughHeadersQuery query (DrillThroughHeadersMessage and InternalDrillthroughHeadersMessage requests). |
| DrillthroughMessageWithHeadersAnswers | Answers sent by data nodes to a query node as a response to a DrillthroughQuery query (DrillThroughMessageWithHeaders request). |
Communication Flows and Associated Diagrams
Discovery Workflow
This page details how several cubes recognize that they should be working as a single application.
When starting a distributed ActivePivot, each cube starts communicating with all the other
future members of the distribution through its JGroups layer. For each clusterId, the first node
to be able to communicate (the node that cannot find anyone to interact with) becomes the JGroups
coordinator.
The distributed ActivePivot can be seen as a complete graph, whose vertices are the distributed cubes, and the edges are open communication channels between two nodes.
A cube's messenger won't communicate with remote instances whose clusterIds (stated in each distributed cube's description) are different from its own.
JGroups also handles cluster security, as explained in Distributed Security.
The JGroups cluster coordinator maintains a View object, including an incremental ID
and a list of all cluster members.
This is equivalent to cutting vertices of the initial graph. By the end of this phase, the initial graph becomes a disconnected graph, whose connected components each form a complete graph and represent a single cluster.
After the JGroups layer has initialized the communications between the nodes of a cluster, the data
nodes send a HelloMessage to each query node of the cluster, making sure that communication is
possible with the query node.
Each cluster can be seen as a complete bipartite graph, one group being the data nodes, the other being the query nodes.
When a query cube starts, it is composed of only one hierarchy: the measure hierarchy made with contributors.COUNT and potentially other measures, like post-processed measures or calculated formulas.
When a data cube starts, it sends an InitialDiscoveryMessage to each query cube already present in
the cluster.
The message contains a serialized version of the data cube's hierarchies: the measure hierarchy with
the aggregate measures and post-processed measures, as well as all the other hierarchies of the data
cube, with their members. Once received and deserialized by the query cube, the data cube's
hierarchies are merged into the query cube's own hierarchies, creating new ones if necessary.
Thus, the query cube topology represents the merger of all its data cubes' topologies.
Since a query cube will potentially receive InitialDiscoveryMessages from dozens of Data Cubes,
there can be a long computing time involved in the processing of these messages, especially if
the data cubes' hierarchies contain many members.
You can monitor the amount of InitialDiscoveryMessages accepted at any given time by a Query Node using the property -Dqfs.distribution.maxPendingDiscoveries=[integer].
Sequence Diagram
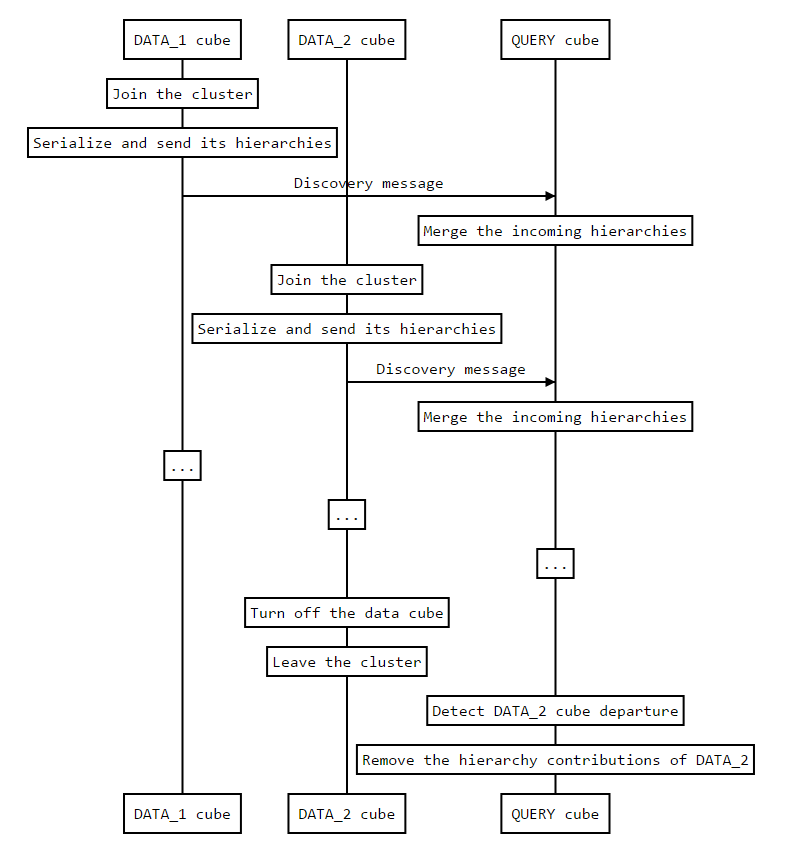
If for some reason a data cube is removed from the cluster, the associated query cubes don't remove the associated
hierarchy contributions immediately.
They will do so after a given period of time that can be set using the removalDelay property. If
the data cube comes back online before this timer expires, and if no new transaction occurred in the
data cube since it has left the cluster, no initial discovery message needs to be sent.
Transaction Workflow
When a transaction occurs in a data cube, some members may appear or disappear. This information needs to be forwarded to each query cube in the cluster. This is done by sending a message containing the new or removed members to each query cube in the cluster. Once received, query cubes update the content of their own hierarchies accordingly.
Sequence Diagram
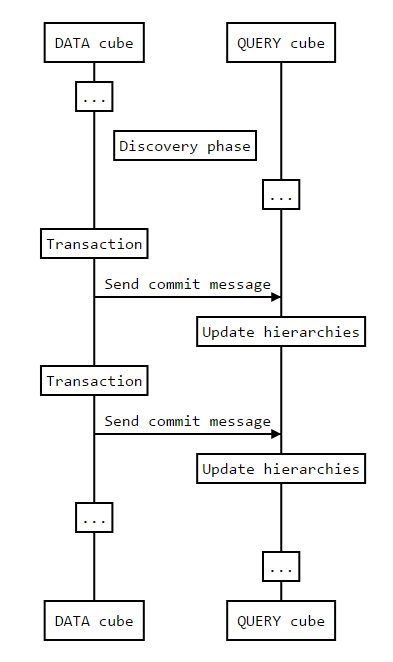
For the sake of simplicity, only one data cube is shown in the diagram.
In a data cube, transactions do not always result in added or removed members. By default, query cubes are still notified when an empty transaction occurs. This can be deactivated by setting
discardEmptyTransactionstotrue.
Query Workflow
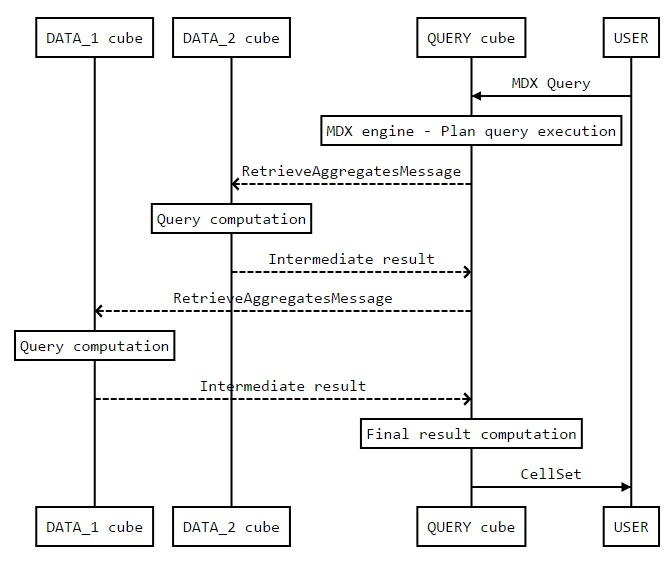
When an MDX query is started on a query cube, the MDX engine plans the GetAggregatesQueries (GAQ)
needed to compute the result and executes them, as it is done on a regular ActivePivot.
A GAQ executed on a query cube is dispatched to the appropriate data cubes. This computation step
is done by the query cube's query plan, in the form of an RetrieveAggregatesMessage.
The way a GAQ is dispatched highly depends on its attributes: the set of locations, the measures and the filters. Not all data cubes may be contacted by the query cube.
Once received by a data cube, the GAQ is computed and the result is sent back to the query cube. Once received, all intermediate results are merged/combined by the query cube before giving it to the MDX engine, which can then build the final result.
In order to reduce the number of messages sent between the data cube and the query cube, a
RetrieveAggregatesMessage computes all the intermediate results that a single data cube must
compute.
Sequence Diagram
Cube Removal Workflow
To leave its cluster, a node must send a leave message to the JGroups coordinator.
For details, see the JGroups documentation on this subject.
If the coordinator tries to leave, a new one is seamlessly selected from the cluster members.
When a member is suspected to have crashed, the coordinator broadcasts a suspicion message to all other members of the cluster. If the coordinator crashes, a new one is seamlessly selected from the cluster members.
A member leaving or crashing induces a change in the View object maintained by the coordinator.
When a data cube leaves the cluster, the query cube is informed by its messenger that the View
object has changed. This Data Node's unique contributions to the global topology are removed from
the query cube's hierarchies if they were not shared with another data cube.
An entire hierarchy can disappear if all of its members are removed.
Sometimes network issues or calculation saturation can cause a data node to be irresponsive for a
short time, triggering a suspicion message from the JGroups coordinator. Since removing that data
node's contributions is an expensive operation, the query cube will wait for a certain time before dropping these contributions, offering the
data node some time to join the cluster again.
When this happens, the data cube will send an EmptyInitialDiscoveryMessage to notify the query cube it hasn't changed its topology.
You can specify the waiting time using the
removalDelayproperty.
In order to distinguish unresponsive data nodes (for instance due to high workload or network issues) from data nodes that left the cluster
gracefully, each data node, when leaving the cluster, will send a GoodbyeMessage notifying the query node about its intent to leave the cluster.
This will immediately trigger an asynchronous task responsible for removing all subsequent contributions of the former. On success, a GoodbyeMessageApplicationEvent is generated. Otherwise,
on failure of the removal task, a GoodbyeMessageApplicationFailureEvent is generated.
When a query cube leaves the cluster, the data cube remains unchanged.
If a query is running when a cube leaves the cluster:
- if the cube has sent a normal leave message, the data from that cube is simply ignored
- if the cube is irresponsive, the query cube waits for results until the query fails due to timeout, thus avoiding "surprise" partial results due to network flakiness.