ETL for SA Overview
As part of the data loading process, the ETL layer handles data manipulation between the file format and the internal datastore structure.
These processes are performed through Column Calculator, Tuple Publisher and Publisher objects.
This section provides an overview of the processes, calculators and publishers used in ETL for the Standardised Approach, starting with dataflow diagrams for SBM, DRC, Trade Attributes and Other SA CSV files.
For information on specific ETL processes applied to individual CSV file types, see the following sections:
- SA ETL for SBM Delta
- SA ETL for SBM Vega
- SA ETL for SBM Curvature
- SA ETL for DRC
- SA ETL for Trade Attributes
- SA ETL for Other Files
Dataflow Diagrams
| SBM | DRC | Trade Attributes | Other |
|---|---|---|---|
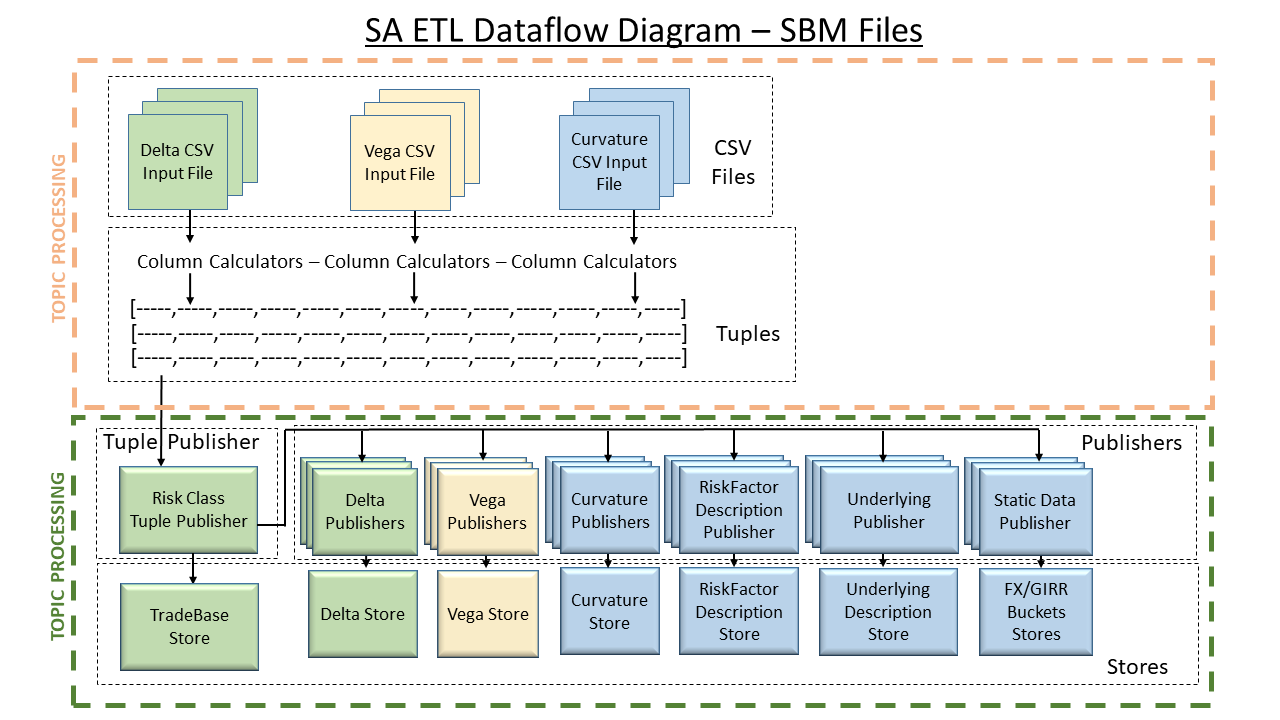 |
 | 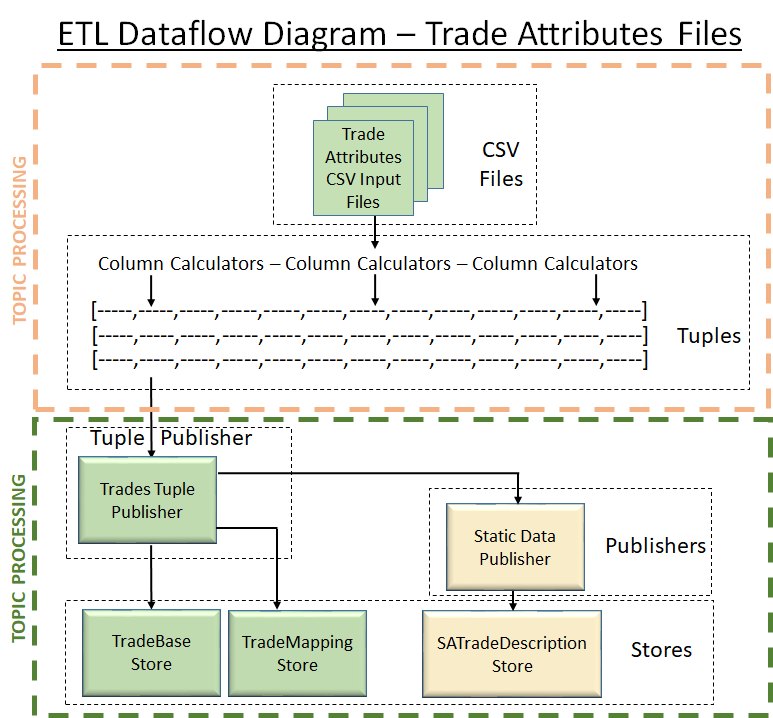 |
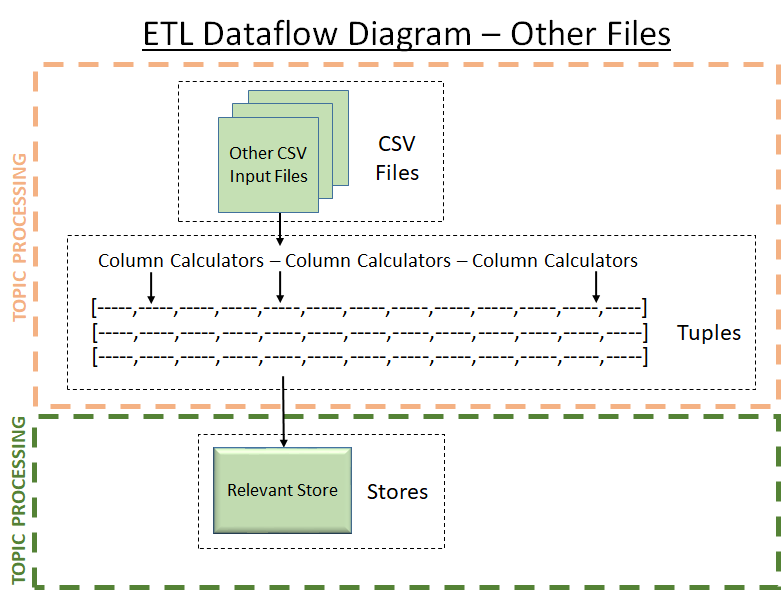 |
Vectorization
Vectorization is performed for Curvature shocked prices. For details, see SA ETL for SBM Curvature.
Sensitivity expansion
If the sensitivity is represented as a vector, it will be automatically expanded into multiple entries. If the sensitivity is a scalar value, this logic is skipped. The SensitivityDates / OptionMaturity and the UnderlyingMaturity (axis 1 and axis 2) will be appended at the end of the Risk Factor. If the Risk Factor contains the specific character sequence “%s”, they will be inserted at the location of this character sequence.
The sensitivities count must be the same as the axis 1 multiplied by axis 2 count.
If the UnderlyingMaturity is empty or contains only one element, it won’t be appended to the risk factor.
If nothing is specified on the input file, the axis will get a default value.
| Measure | Axis 1 | Axis 1 default value | Axis 2 | Axis 2 default value |
|---|---|---|---|---|
| Delta | SensitivityDates | 0Y | N/A | |
| Vega | OptionMaturity | 6M;1Y;3Y;5Y;10Y | UnderlyingMaturity | 1Y |
Sample
| AsOfDate | TradeId | DeltaCcy | DeltaSensitivities | RiskClass | SensitivityDates | RiskFactor | Type | GIRRCcy | Underlying | CSRQuality | CSRSector | EquityEconomy | EquityMarketCap | EquitySector | CommodityLocation | FxCounterCcy | Optionality | CSRRating | FxComplexDelta | FxOtherCcy | FxDividerEligibility | Bucket | ||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 2018-09-28 | COM_OPT_milk b6bd4040 | EUR | 11071.37;8971.90;4940.98;518.54;1394.11 | Commodity | 0.25Y;0.5Y;1Y;2Y;3Y | Livestock & dairy | USD | milk | Zone1 | Y |
Will generate
| RiskFactor | Sensitivity |
|---|---|
| milk Zone1 0.25Y | 11071.37 |
| milk Zone1 0.5Y | 8971.90 |
| milk Zone1 1Y | 4940.98 |
| milk Zone1 2Y | 518.54 |
| milk Zone1 3Y | 1394.11 |
Normalization
Database normalization, or simply normalization, is the process of restructuring a relational database in accordance with a series of so-called normal forms to reduce data redundancy and improve data integrity.
In the FRTB Accelerator, the Delta, Vega, Curvature, and Trade files are flat. However, the datastore schema is normalized. Hence the ETL has to normalize the data as it is loaded.
This is mainly required for the RiskFactorDescription and UnderlyingDescription fields included within the Delta, Vega and Curvature files.
For example, when a row of a Delta sensitivities file is processed, (approximately) the first half of the row goes into the delta sensitivities store while (approximately) the second half of the row goes into the RiskFactorDescription and UnderlyingDescription stores. There is a one-to-one correspondence (modulo vectorization) between rows in the file and rows in the sensitivities store. However, multiple rows in the file will include the same data for the RiskFactorDescription and UnderlyingDescription (i.e. the description of the risk factor).
It is the many-to-one references between the delta store and the RiskFactorDescription and UnderlyingDescription store which provide the normalization.
Column Calculators
Column calculators are used to fill in fields that don’t have values in the store, and to define the available fields in a row loaded from a file without depending on the datastore setup.
Tuple Publishers
The tuple publishers used here link the collections of rows to the base store and to publishers handling other stores, sending only the relevant fields in the row. - Normalization
The publishers perform the vectorization and interpolation required by
individual risk classes and measures, using the PublisherUtils utility
class.