Useful MDX examples to run non-trivial analysis in ActivePivot
Advanced MDX Queries
With the new MDX engine (since ActivePivot 4.3.0) business users can perform more complex queries without necessarily having to ask their IT team to write post-processors.
This section features some useful examples of using MDX to run non-trivial analysis in ActivePivot.
Books that Represent 80% of VAR
The TopCount function returns the specified number of elements with the highest values. But in some cases you may want to retrieve the members with the highest values that contribute to x% of the grand total. There is an Mdx function for this: TopPercent
The following query will retrieve the books with the highest VaR that contribute to 80% of the VaR of all the books.
SELECT
{
{[Book].[ALL].[AllMember]}
,TopPercent
(
[Book].[ALL].[AllMember].Children
,80
,[Measures].[historical.VaR]
)
} ON ROWS
FROM [VarCube]
WHERE
[Measures].[historical.VaR]
| Grand Total | 10,495.76 |
|---|---|
| Book_08 | 4,281.17 |
| Book_45 | 1,610.38 |
| Book_39 | 634.95 |
| Book_25 | 385.52 |
| Book_34 | 359.45 |
| Book_13 | 336.94 |
| Book_10 | 270.11 |
| Book_15 | 260.47 |
| Book_28 | 249.27 |
| Book_09 | 207.30 |
| Book_07 | 192.07 |
Calculated Measure Based on Member Value
Here is an MDX query that displays in the column newMeasure the value of contributors.COUNT if the bookId is 0 or 1,
else pnl.SUM is displayed.
Here is the query:
WITH
Member [Measures].[newMeasure] AS IIF(
[Bookings].CurrentMember IS [Bookings].[Desk].[DeskA].[0] OR [Bookings].CurrentMember IS [Bookings].[Desk].[DeskA].[1],
[Measures].[contributors.COUNT],
[Measures].[pnl.SUM]
)
SELECT NON EMPTY {
[Measures].[newMeasure],
[Measures].[contributors.COUNT],
[Measures].[pnl.SUM]
} ON COLUMNS,
NON EMPTY DrilldownMember(
[Bookings].[Desk].[DeskA],
{
[Bookings].[ALL].[AllMember].[DeskA]
}
) ON ROWS
FROM [EquityDerivativesCube]
| Measures | |||
| Desk ->BookId | newMeasure | contributors.COUNT | pnl.SUM |
| Total DeskA | -419221.5099999999 | 8312 | -419,221.51 |
| 0 | 858 | 858 | -55,139.82 |
| 1 | 818 | 818 | -30,642.60 |
| 2 | -44790.53999999996 | 871 | -44,790.54 |
| 3 | -26577.700000000044 | 743 | -26,577.70 |
| 4 | -32890.090000000026 | 863 | -32,890.09 |
| 5 | -41814.00000000004 | 840 | -41,814.00 |
| 6 | -52157.62999999997 | 862 | -52,157.63 |
| 7 | -32385.66999999997 | 833 | -32,385.67 |
| 8 | -30945.900000000016 | 806 | -30,945.90 |
| 9 | -71877.56000000001 | 818 | -71.877.56 |
Daily Turnover Change
With MDX functions like PrevMember and NextMember you can write formulas that compare the measure values between 2 days/weeks/months/years.
For instance :
([Measures].[Turnover.SUM]/([Measures].[Turnover.SUM], [Time].CurrentMember.PrevMember) -1) * 100
... where:
- [Measures].[Turnover.SUM] has the same value as ([Measures].[Turnover.SUM], [Time].CurrentMember) which is the turnover for the current member on the time dimension
- ([Measures].[Turnover.SUM], [Time].CurrentMember.PrevMember) is the turnover for the member that is before the current member on the time dimension
- the final expression returns the relative growth between the 2 members If you put [Time].[Day].Members on one of the axes, you will have the daily turnover change. If you put [Time].[Month].Members on one of the axes, you will have the monthly turnover change.
The final MDX query will look like this:
WITH
MEMBER [Measures].[Daily Turnover Change] AS
IIF
(
[Time].CurrentMember.PrevMember
IS NULL
,NULL
,
([Measures].[Turnover.SUM]/([Measures].[Turnover.SUM], [Time].CurrentMember.PrevMember) -1) * 100
)
SELECT
NON EMPTY
[Time].[Day].MEMBERS ON ROWS
FROM [Amazon]
WHERE
[Measures].[Daily Turnover Change]
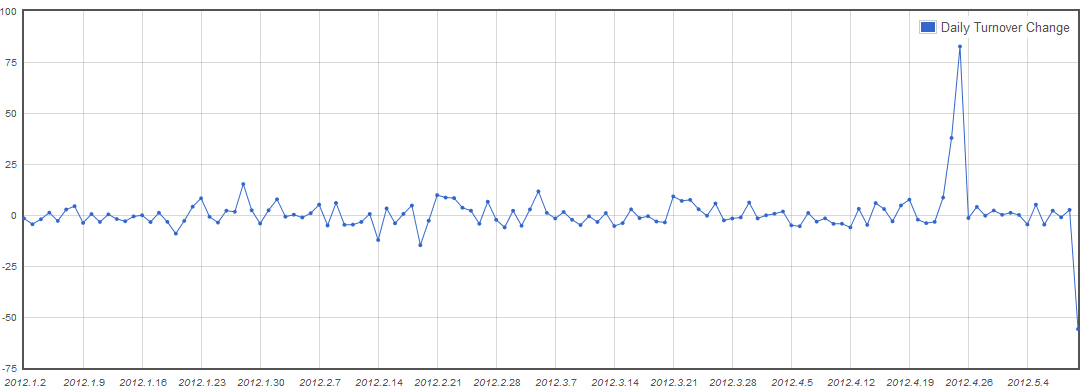
The IIf is used to handle the value of the formula for the first day. [Time].CurrentMember.PrevMember does not exist for the first day; it will be null.
Date Ranges
Dates
All dates:
[AsOfDate].[AsOfDate].[AsOfDate].Members
All dates until:
[AsOfDate].[AsOfDate].[AsOfDate].[Wed Oct 17 00:00:00 CEST 2012] : null
All dates from:
null : [AsOfDate].[AsOfDate].[AsOfDate].[Wed Oct 17 00:00:00 CEST 2012]
Day to Day Differences
This section explains how to use MDX calculated members to compute differences between adjacent members. A typical example would be the evolution of delta or pl from one business date to the next.
The example here can be deployed on the sandbox project by cut and paste of the following MDX into ActivePivot Live query editor.
The following table shows an MDX calculated member called DIFF which is evaluated as the difference in delta.SUM from one member in the dates dimension to the next.
| 21-Jun-2012 | 20-Jun-2012 | 19-Jun-2012 | |
|---|---|---|---|
| DIFF | 17,730.64 | -74.090.05 | |
| delta.SUM | -364,364.78 | -346,635.14 | -420,725.19 |
The key MDX part to focus on is the definition of a calculated member (see the WITH MEMBER clause) called DIFF.
It is computed as the difference between the current value and the previous value and as you can see from the screen shot – it is generic in that it works not only for T against T-1 but also at T-1 against T-2 and will work across all pairs of members on the date dimension.
Another nice MDX feature is the FORMAT clause in the the query.
WITH MEMBER [Measures].[DIFF] AS
IIF
(
[HistoricalDates].CurrentMember.PrevMember
IS NULL
,NULL
,
[Measures].[delta.SUM]
-
(
[Measures].[delta.SUM]
,[HistoricalDates].CurrentMember.PrevMember
)
)
,FORMAT = "#,###.00"
SELECT
NON EMPTY
{
[Measures].[DIFF]
,[Measures].[delta.SUM]
} ON ROWS
,NON EMPTY
Hierarchize
(
{
[HistoricalDates].[AsOfDate].MEMBERS
}
) ON COLUMNS
FROM [EquityDerivativesCube]
Using relative date functions
Using PrevMember and NextMember functions makes your query dependant on the level comparator use for the AsOfDate
level. Plus, you may not have members for every day in a given period, for instance only working days may be present so you won't be able to compare delta.SUM on Monday because there is no data for the previous day. To free yourself from those confines, you can use specific MDX date functions.
Use case
Create a measure in mdx that computes the difference of delta.SUM between Today and Yesterday. This can be achieve
with ActivePivot, form 4.4.6 version onwards thanks to newly implemented relative date functions (DateDiff, DateAdd and Now).
Query
WITH
Set [toto] AS Order(
Filter(
[Time].[HistoricalDates].[AsOfDate].Members,
IsDate(
[Time].[HistoricalDates].CurrentMember.MemberValue
) AND (
DateDiff(
"d",
[Time].[HistoricalDates].CurrentMember.MemberValue,
Now(
)
) = 1 OR DateDiff(
"d",
[Time].[HistoricalDates].CurrentMember.MemberValue,
Now(
)
) = 0
)
),
[Time].[HistoricalDates].CurrentMember.MemberValue
)
Member [Measures].[Diff btw Today - Yesterday] AS IIF(
Count(
[toto]
) = 2,
(
[Measures].[delta.SUM],
[toto].Item(
1
)
) - (
[Measures].[delta.SUM],
[toto].Item(
0
)
),
NULL
),
FORMAT_STRING="#,###.00"
SELECT NON EMPTY {
[Measures].[Diff btw Today - Yesterday]
} ON COLUMNS,
NON EMPTY Hierarchize(
[Bookings].[Desk].[BookId].Members
) ON ROWS
FROM (
SELECT [Bookings].[Desk].[ALL].[AllMember].[DeskA] ON COLUMNS
FROM [EquityDerivativesCube]
)
Explanation
First, create a Named Set composed of the two dates: today and yesterday. This is done by taking the members of the
hierarchy for which the difference of days from Now (that is to say currently) is equal to 0 or 1. Then, it is sorted
in descending order and we create a calculated member for the difference of delta.SUM between these two dates.
Result
| Measures | ||||||
|---|---|---|---|---|---|---|
| Desk | BookId | Diff btw Today - Yesterday | current delta.SUM | delta.SUM today - 1 | ||
| DeskA | 0 | 6 289,98 | -47 029,90 | -53 319,86 | ||
| 1 | -3 163,21 | -27 243,67 | -24 080,46 | |||
| 2 | -14 404,42 | -37 249,83 | -22 845,41 | |||
| 3 | 7 060,66 | 33 474,49 | 26 413,83 | |||
| 4 | 11 942, 06 | -61 702,55 | -73 644,61 | |||
| 5 | -1 013,81 | 43 947,61 | 44 961,42 | |||
| 6 | 4 206,75 | -55 789,63 | -59 996,38 | |||
| 7 | -4 151,88 | 2 800,65 | 6 952,53 | |||
| 8 | 7 953,25 | -38 842,98 | -46 796,23 | |||
| 9 | -12 674,60 | -21 805, 47 | -9 130,87 | |||
Changing
DateDiff("d", [Time].[HistoricalDates].CurrentMember.MemberValue, Now()) = 1 //difference is equal to 1
to
DateDiff("d", [Time].[HistoricalDates].CurrentMember.MemberValue, Now()) = 7 //difference is equal to 7
compares the current delta.SUM value to the one 7 days ago.
Further more, if it is Monday, you may want to compare the value to the previous one, the week before, on Friday. To do that, you must change a condition in the filter method:
Filter(
[Time].[HistoricalDates].[AsOfDate].Members,
IsDate([Time].[HistoricalDates].CurrentMember.MemberValue)
AND (
DateDiff("d", [Time].[HistoricalDates].CurrentMember.MemberValue, Now()) = IIf(Weekday(Now()) = 2, 3, 1) //The day
before or 3 days before if it's Monday (second week day)
OR
DateDiff("d", [Time].[HistoricalDates].CurrentMember.MemberValue, Now()) = 0
)
)
Distinct Count
The contributors.COUNT native measure counts the number of facts that contribute to a cell.
Often we are interested in counting at a higher level:
- How many (distinct) traders have booked trades
- How many (distinct) passengers have been transported in a set of flights
- ...
This can be achieved directly in MDX:
In a first step you list all the members to count, in the context of the currently evaluated cell. For that you use the DESCENDANTS funtion and the CurrentMember function to set the context. Then you count the members with the COUNT function, making sure you only to count the non empty ones (for which the current measure, or contributors.COUNT by default actually returns something).
In the example below, for each traded product, we count the number of (distinct) desks where the product is traded.
WITH
Member [Measures].[Desk Count] AS Count(
Descendants(
[Bookings].[Desk].CurrentMember,
[Bookings].[Desk].[Desk]
),
EXCLUDEEMPTY
)
SELECT NON EMPTY Hierarchize(
DrilldownLevel(
[Underlyings].[Products].[ALL].[AllMember]
)
) ON ROWS
FROM [EquityDerivativesCube]
WHERE [Measures].[Desk Count]
DISTINCT COUNT can also be achieved with a post processor: the leaf count post processor, and with a better performance. But the MDX approach is dynamic and available for all the hierarchies, while the post processor must be configured and deployed with the cube.
Exclude an intersection of two hierarchies
- Use the Except and CrossJoin functions.
- Use the Crossjoin in the first argument of the Except function to return all the possible Tuples and then give the intersection (Tuple) that you want to exclude in the second argument.
- The result is a Set that can then be used on a Pivot axis.
Exclude intersection of Member A and Member B from the cross join of Hiearchy A and Hierarchy B
_______________________________________________________________________________________________
Except(
Crossjoin(
[Dimension A].[Hierarchy A].[Level A].Members,
[Dimension B].[Hierarchy B].[Level B].Members
),
(
[Dimension A].[Hierarchy A].[Level A].[Member A],
[Dimension B].[Hierarchy B].[Level B].[Member B]
)
)
see Working with Members, Tuples, and Sets (MDX).
Filter Dimension Members Based on Their Names
When you manipulate high cardinality dimensions, you may often want to focus only on particular subsets of members and the selection of those members might be tricky at times, based on particular naming convention.
MDX allows you to do quite fine selections by using the Filter function in association with the Caption function.
We can illustrate this use case against the ActivePivot sandbox by drilling down the PnL measure w.r.t. Underlyings.
Non-Filtered Members
SELECT
NON EMPTY Hierarchize({DrilldownLevel({[Underlyings].[ALL].[AllMember]})}) ON ROWS
FROM [EquityDerivativesCube]
WHERE ([Measures].[pnl.SUM])
| Underlyings | pnl.SUM |
|---|---|
| Grand Total | -21,223.46 |
| EUR | -14,033.05 |
| GBP | -7,190.20 |
| USD | -5,633.21 |
| JPY | -5,792.54 |
| CHF | 16,675.98 |
| ZAR | -5,250.44 |
Filtering Members that Start With...
If you want to see only currencies starting from letter C to H, you will perform your query, not on the entire cube, but on a filtered cube. So the query FROM section needs to be updated as in the following:
SELECT NON EMPTY Hierarchize({DrilldownLevel({[Underlyings].[ALL].[AllMember]})}) ON ROWS
FROM
(SELECT Filter([Underlyings].[UnderlierCurrency].Members, ([Underlyings].CurrentMember.Caption>="C" AND [Underlyings].CurrentMember.Caption<="H"))
ON COLUMNS FROM [EquityDerivativesCube])
WHERE ([Measures].[pnl.SUM])
| Underlyings | pnl.SUM |
|---|---|
| Grand Total | -125.49 |
| EUR | -12,757.20 |
| GBP | -8,332.57 |
| CHF | 20,964.28 |
Note that the criteria in the filter section can be more complex to suit specific needs. For instance, you may input more characters to refine your selection (e.g. instead of currency starting from C, you can select currency starting from CI).
Filtering Members that End With...
If you want to see only currencies ending with letter R or below letter R, you can update the criteria using the Right function. Note if you want to add more letter, you will need to increase the index of the Right function.
(SELECT Filter([Underlyings].[UnderlierCurrency].Members,(Right([Underlyings].CurrentMember.member_caption,1)>="R"))
| Underlyings | pnl.SUM |
|---|---|
| Grand Total | -9,153.53 |
| EUR | -7,194.67 |
| GBP | -5,260.58 |
| CHF | 3,301.72 |
MDX keywords member_caption or Caption are interchangeable.
Filter for a Holiday Calendar - Excluding members from a hierarchy
Since ActivePivot Live 2.9, one can save filters as bookmarks. A nice use case for this is a holiday calendar to exclude dates from a view of VaR and Business Day, where VaR is calculated MON-FRI regardless, but should not be shown for public holidays.
The following set can be saved as a bookmark and applied to any query.
SET UkWorkingDays AS
Except(
{
[Time].[Valuation Time].[Valuation Date].Members
},
{
[Time].[Valuation Time].[Valuation Date].[Wed Jan 01 00:00:00 CET 2014],
[Time].[Valuation Time].[Valuation Date].[Fri Apr 11 00:00:00 CET 2014],
[Time].[Valuation Time].[Valuation Date].[Mon Apr 14 00:00:00 CET 2014],
...,
...
}
)
The MDX Except function takes a set in the first argument and excludes all members of the set in the second argument.
With the above filter, New Year's day, Good Friday and Easter Monday will be excluded from the Valuation Time dimension (hierarchy in AP5).
Filtering on Measure Values
We can filter members based on a set of conditions on a measures values with the IIf function and operators such as AND, OR, >, < etc...
Note that for filtering based on a single condition, one may simply use the Filter MDX function: see http://msdn.microsoft.com/en-us/library/ms146037.aspx
For instance :
Select all Products that have a contributor count between 50 and 1000,
and all Products with a count above 1000 on a separate column
The MDX query will look like this:
WITH
MEMBER [Measures].[LargeCount] AS
IIF
(
[Measures].[contributors.COUNT] <= 1000
AND
[Measures].[contributors.COUNT] >= 50
,[Measures].[contributors.COUNT]
,null
)
MEMBER [Measures].[VeryLargeCount] AS
IIF
(
[Measures].[contributors.COUNT] > 1000
,[Measures].[contributors.COUNT]
,null
)
SELECT
NON EMPTY
Hierarchize
(
{
DrillDownLevel({[Product].[ALL].[AllMember]})
}
) ON ROWS
,{
[Measures].[contributors.COUNT]
,[Measures].[LargeCount]
,[Measures].[VeryLargeCount]
} ON COLUMNS
FROM [VarCube]
| Product | contributors.COUNT | LargeCount | VeryLargeCount |
|---|---|---|---|
| Grand Total | -20,962 | 20,962.00 | |
| ABCP | 40 | ||
| CDO^2 | 40 | ||
| CDSNthDefault | 40 | ||
| CDSNthLoss | 40 | ||
| CLN CDS | 40 | ||
| CcySwap | 40 | ||
| Convertible Bond | 40 | ||
| Corporate Bond | 472 | 472.00 | |
| Corporate Loan | 72 | 72.00 | |
| Covered Bond | 40 | ||
| Debt Security | 668 | 668.00 | |
| EQ Derivative | 1,713 | 1,713.00 | |
| FX Derivative | 252 | 252.00 | |
| FX Vanilla | 4,502 | 4,502.00 | |
| Government Bond | 1,904 | 1,904.00 | |
| IR Derivative | 4,732 | 4,732.00 | |
| IR Vanilla | 3,787 | 3,787.00 | |
| Money Market | 40 | 3,787.00 | |
| Money Market (CP) | 36 | ||
| Quasi Government | 116 | 116.00 | |
| Single-name CDS | 40 | ||
| Supra | 80 | 80.0 | |
| TRS | 40 | ||
| UNKNOWN | 468 | 468.00 | |
| Vanilla Equity | 1,459 | 1,459.00 |
Filtering on Measure Values in MDX to include/exclude data from a view
In order to filter a data set on an existing bookmark such that the view only displays what you want to filter for, the MDX query can be injected with a FILTER without the need to create new member measures.
The following MDX snippet from a bookmark only showing Bookings and their contributor counts illustrates its use.
SELECT NON EMPTY {
[Measures].[contributors.COUNT]
} ON COLUMNS,
NON EMPTY FILTER(
Hierarchize(
[Booking].[Book].Members
),
[Measures].[contributors.COUNT] > 500
) ON ROWS
FROM [EquityDerivativesCube]
From the Microsoft description of a filter http://msdn.microsoft.com/en-us/library/ms146037.aspx the syntax for a filter is thus:
Filter(Set_Expression, Logical_Expression)
In our example above, the Set_Expression parameter is
Hierarchize(
[Booking].[Book].Members
)
and the Logical_Expression parameter is
[Measures].[contributors.COUNT] > 500
This filter will now only allow the displaying of Booking entities where the contributor count is more than 500.
| Book | contributors.COUNT |
|---|---|
| LONDON | |
| FICC | |
| Euro Credit Derivati... | 616 |
| Rates 2 | 753 |
| NEWYORK | |
| FICC | |
| Rates 1 | 566 |
| undefined | |
| undefined | |
| CNEWBOOK | 960 |
A possible use-case may be where a measure such as P&L is below a certain interested value, and this bookmark may be saved to explicitly display the biggest loss-making desks/books.
Another possible use-case may be in conjunction with a measure-quality measure where you are only interested in those bookings where the data quality is less than 100%.
For example, [Measures].[pnlVector.QUALITY] < 1 where the pnlVector.QUALITY measure is a percentage of the contributors count.
Measure as Mathematical Formula
Measures can be added with a mathematical formula built with operators and operands (scalars or other measures).
For instance :
Full VaR = Square root of sum of Square of historical VaR and Square of stress VaR
In other words:
fullVaR = (historicalVaR^2 + stressVaR^2) ^ (1/2)
Also we want to format the result using a 2 decimals precision and thousands separator, such as 1,123,456.89
The MDX query will look like this:
WITH
/* full value-at-risk combining historical and stress values */
MEMBER [Measures].[fullVaR] AS
([Measures].[historical.VaR] ^ 2 + [Measures].[stress.VaR] ^ 2) ^ 0.5
,FORMAT = '#,###.##'
SELECT
NON EMPTY
Hierarchize
(
{
DrillDownLevel({[ProfitCenter].[ALL].[AllMember]})
}
) ON ROWS
,NON EMPTY
{
[Measures].[historical.VaR]
,[Measures].[stress.VaR]
,[Measures].[fullVaR]
} ON COLUMNS
FROM [VarCube]
| Real-time PushPivot View | |||
| historical.VaR | stress.VaR | fullVaR | |
| Grand Total | 10,495.76 | 10,503.39 | 14,848.64 |
| ProfitCenter_A | 10,495.76 | 10,503.39 | 14,848.64 |
| ProfitCenter_B | 1,124.85 | 1.169.57 | 1,655.03 |
| ProfitCenter_C | 1,225.42 | 1,227.46 | 1,734.45 |
| ProfitCenter_D | 2,101.37 | 2,101.13 | 2,971.62 |
| ProfitCenter_E | 295.74 | 293.94 | 416.97 |
| ProfitCenter_F | 4,698.93 | 4,689.38 | 6,638.54 |
Recurrence Relations
For advanced time series analysis and visualisation use cases recursive MDX functions can be used. First let's consider a time dimension where each member represents a unit of time, with a cumulative measure along the dimension, along with a measure summed at each unit of time. The cumulative measure could easily be the accumulated cash value of inventory (cash, pledgeable assets, SKUs, oxen, or otherwise) and the summed measure could easily be the amount paid for acquisition of inventory at each point in time. This would give an interesting summary of inventory at any point in time.
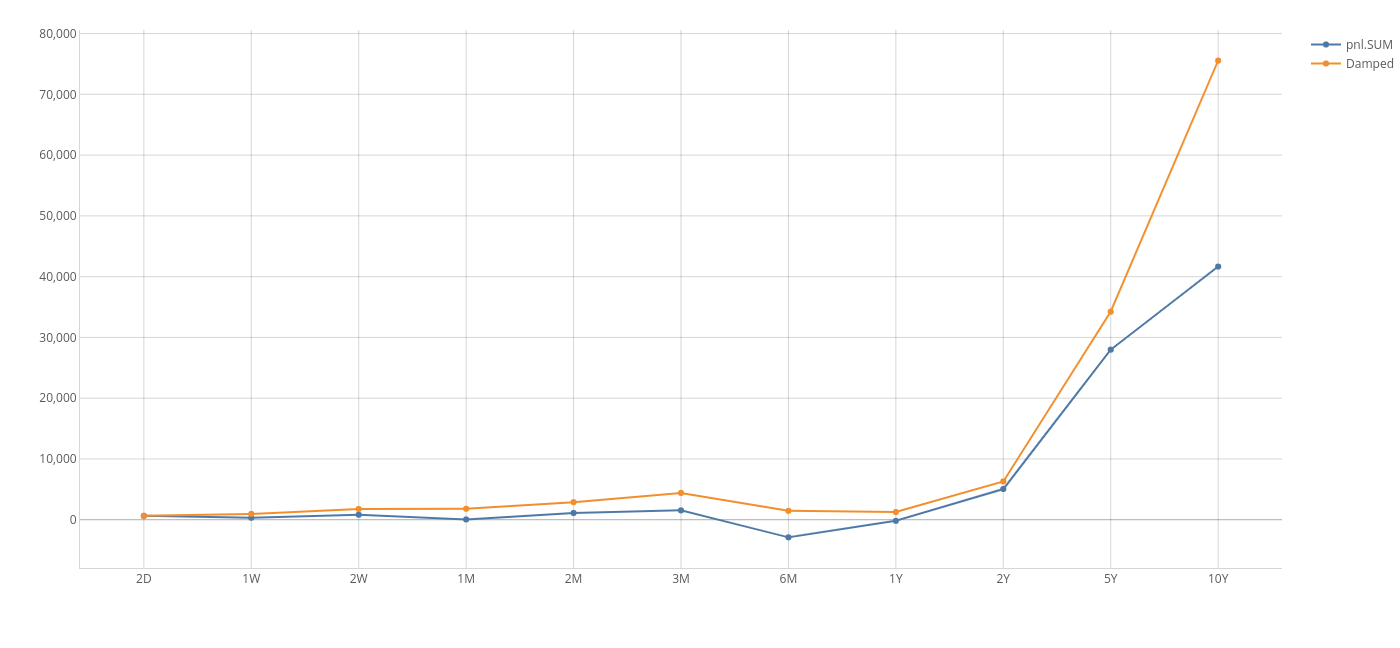
Perhaps the cash value of inventory does not just accumulate - it may be associated with an opportunity cost, a fixed storage or administrative cost x so that the value of an inventory unless utilised for some business purpose decays to zero with some half life. Such a scenario could easily model the maintenance of a liquidity buffer or the warehousing cost of unsold electronic widgets with otherwise have a nominal cash value. To do this we need an MDX recursive measure with a damping factor.
The following MDX can be applied on the sandbox project to acheive such calculation. Here, pnl.SUM represents the cumulative measure:
WITH
Member [Measures].[Damped] AS IIF(
[Time].[TimeBucket].CurrentMember.PrevMember IS NULL,
[Measures].[pnl.SUM], //this is the base case of the recurrence relation
(
[Time].[TimeBucket].CurrentMember,
[Measures].[pnl.SUM]
) + 0.99 * (
[Time].[TimeBucket].CurrentMember.PrevMember,
[Measures].[Damped]
) // else recurse in the previous member, with a damping factor representing a 1% carrying cost
)
SELECT
NON EMPTY {
[Measures].[contributors.COUNT],
[Measures].[Damped]
} ON COLUMNS,
NON EMPTY [Time].[TimeBucket].[DateBucket].Members ON ROWS
FROM [EquityDerivativesCube]
CELL PROPERTIES VALUE, FORMATTED_VALUE, BACK_COLOR, FORE_COLOR, FONT_FLAGS
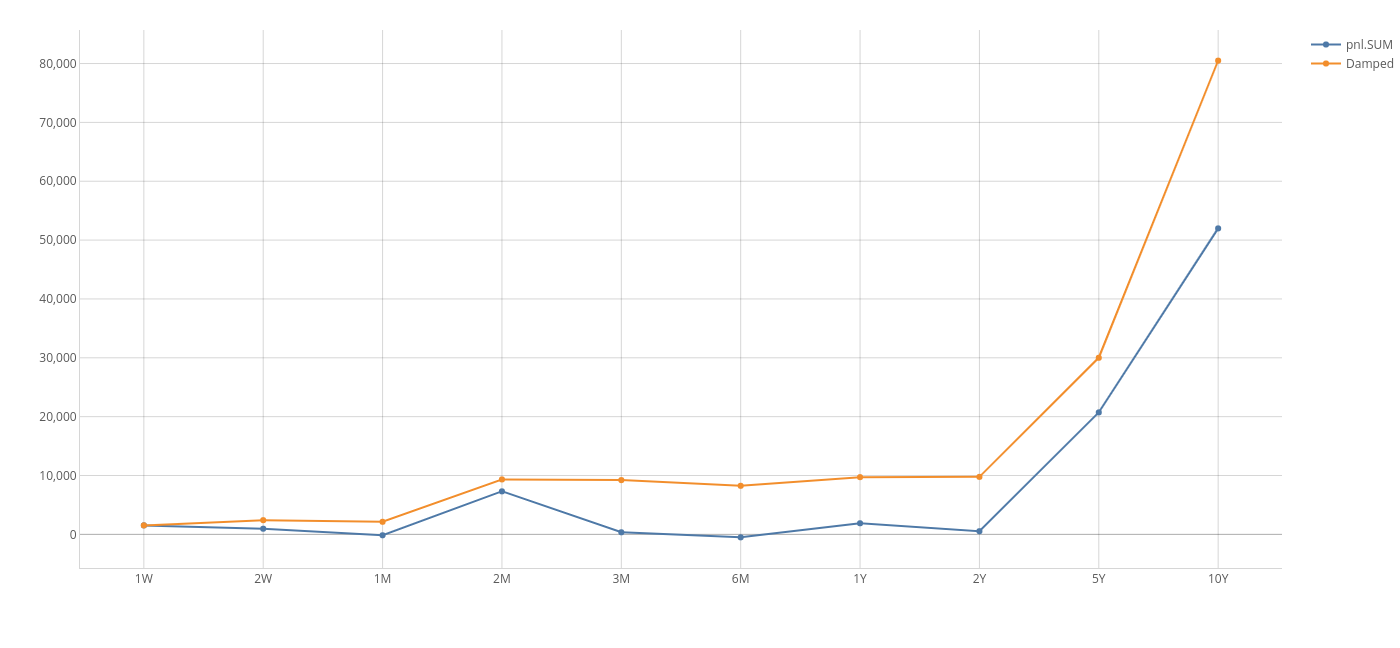
This gives a very appealing graph, and different assumptions can be tested on the fly, without IT support such as "What happens to my bottom line if the per unit cost of storing an unsold tablet rises from 1% per time unit to 5%?" or "What is the opportunity cost imposed by my excess liquidity buffer if interest rates rise by 1%?
Below is a comparison between accumulation in the presence of costs and with a 1% carrying cost.
Below is a comparison between a 1% carrying cost and a 5% carrying cost.
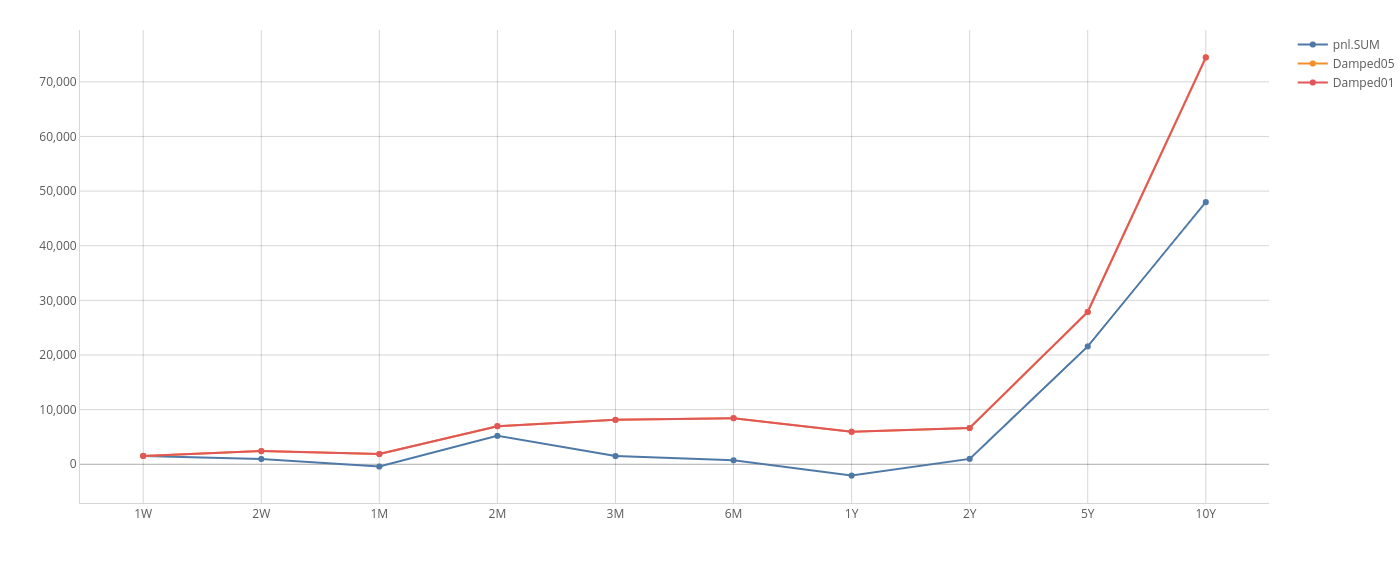
When using recursion you need to be careful to ensure that your relation terminates and has low computational complexity - symptomatic of failure to achieve this is a stack overflow!
Show VaR Only for Trades that Were not Present in the Previous Day
WITH
Member [Measures].[New Trades VaR] AS IIF(
(
[DAY].CurrentMember.NextMember,
[TRADE_ID].CurrentMember,
[Measures].[contributors.COUNT]
) > 0,
NULL,
[Measures].[VaR]
)
SELECT NON EMPTY (
[DAY].[DAY].Members,
[Measures].[New Trades VaR]
) ON COLUMNS,
NON EMPTY
(
[TRADE_ID].[TRADE_ID].Members
)
) ON ROWS
FROM [YOUR_CUBE]
This is example works for trade-level VaR. To calculate the VaR for all trades not present in the previous day, the measure would need to be the sum of the VaR Vector, which could then be fed into a PostProcessor to calculate the percentile.
Top 3 Underlyings per Country
You may know the TopCount function, which is very helpful when you want to keep only the members with the highest values.
Now, imagine that you have in your cube the dimensions Underlyings and Geography and you want to retrieve for each region the 3 underlyings that have the highest PnL.
You cannot do this with only TopCount, you will have to use Generate. This functions acts like a For loop.
Here is the mdx that will do what we want
SELECT
NON EMPTY
Generate
(
[Geography].[Region].MEMBERS
,TopCount
(
{[Geography].CurrentMember} * [Underlying].[ALL].[AllMember].Children
,3
,[Measures].[TotalPnl.SUM]
)
) ON ROWS
,{[Measures].[TotalPnl.SUM]} ON COLUMNS
FROM [PnlCube]
| TotalPnl.SUM | ||
|---|---|---|
| Asia | 600728 | 0 |
| Europe | IAP BARC BRBY | 6,559 1,899 9,33 |
| North America | AAPL GS GE | 16,584 1,434 -36 |
Here is how we can add the total per region:
SELECT
NON EMPTY
Generate
(
[Geography].[Region].MEMBERS
,{
{
([Geography].CurrentMember, [Underlying].[ALL].[AllMember])
}
,TopCount
(
{[Geography].CurrentMember} * [Underlying].[ALL].[AllMember].Children
,3
,[Measures].[TotalPnl.SUM]
)
}
) ON ROWS
,{[Measures].[TotalPnl.SUM]} ON COLUMNS
FROM [PnlCube]
| TotalPnl.SUM | |
|---|---|
| Total Asia | 0 |
| 600728 | 0 |
| TotalEurope | -25,841 |
| IAP | 6,559 |
| BARC | 1,899 |
| BRBY | 933 |
| Total North America | 10,986 |
| AAPL | 16,584 |
| GS | 1,434 |
| GE | -36 |