Experimental feature: Distributed Data Roll Over (without downtime)
The data roll over feature means that data can be moved from one cube to another seamlessly.
A classic use-case is to partition data cubes by time. For example, the most recent dates are into an in-memory cube, while other historical dates are in an external database with a Direct Query cube. With such design comes the need to move the data corresponding to the oldest dates from the in-memory cube to the Direct Query cube, so we free some memory for the next dates.
In addition, it is also possible to temporarily load a datastore data node for some historical date for a quick analysis.
Allowing data overlap
Atoti can now handle data overlap. This means it is possible to have several data cubes with duplicated data.
For more information about query nodes and data nodes responsibilities, see the distribution overview article.
The query node will ensure the correct distribution by choosing for each query which data node to use. The datastore nodes will have a higher priority than the Direct Query nodes.
This means that a version of the data is available at all times, so there is no inconsistency in query results. In addition, there is no need to restart cubes, the query node will discover data nodes as they are started.
The activation of this feature is done at start up like this:
StartBuilding.cube("MyQueryCube")
.asQueryCube()
.withClusterDefinition()
.withClusterId("MyCluster")
.withMessengerDefinition()
.withLocalMessenger()
.withNoProperty()
.end()
.withApplication("MyApplication")
.withDistributingLevels(distributingLevels)
.withProperty(
IQueryClusterDefinition.HORIZONTAL_DATA_DUPLICATION_PROPERTY, Boolean.toString(true))
.end()
.build();
This feature is not compatible with polymorphic distribution.
Atoti server will not ensure that the facts associated with a member of the distributing level are exactly the same across all replicas.
This feature does not represent a full distributed transaction.
Example: date roll over
In order to free some memory for the new date 104, the data for the date 101 needs to be transferred from the in-memory cube to the Direct Query cube:
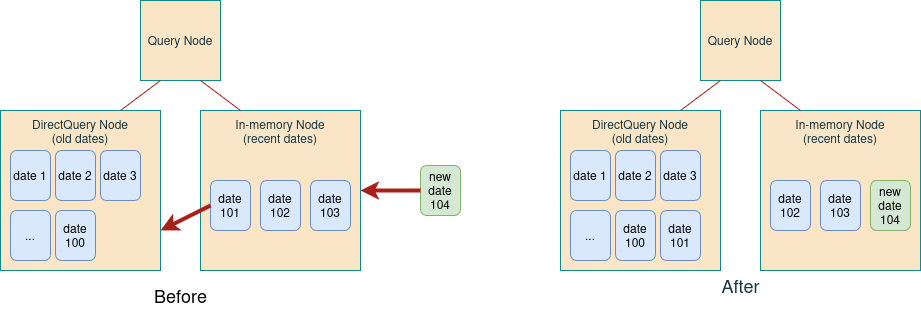
The workflow is:
- Create the Date 101 node in Direct Query
- Delete the Date 101 node in the datastore
- Create the Date 104 node in the datastore
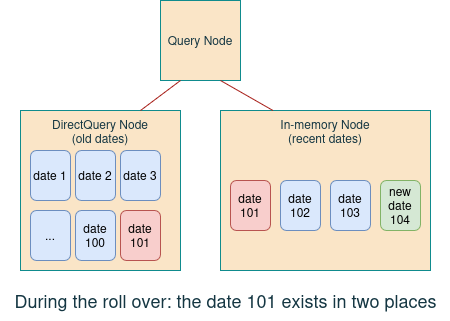 The duplicated data will exist and be visible by the query node in both data nodes (the datastore one
and the Direct Query one). So the query results will remain consistent.
The duplicated data will exist and be visible by the query node in both data nodes (the datastore one
and the Direct Query one). So the query results will remain consistent.
With the data overlap, we can even improve this workflow be having all the dates in Direct Query. The workflow becomes:
- Delete the Date 101 node in the datastore
- Create the Date 104 node in the datastore
All nodes can share the same data source.
Future developments
Atoti is currently working to add the possibility to manage data nodes priorities.