Database Overview
Atoti cubes work on top of a database. This database can be either ActiveViam's Datastore, an external database, or a blend of the two. DirectQuery is the Atoti component allowing to access external databases on the fly.
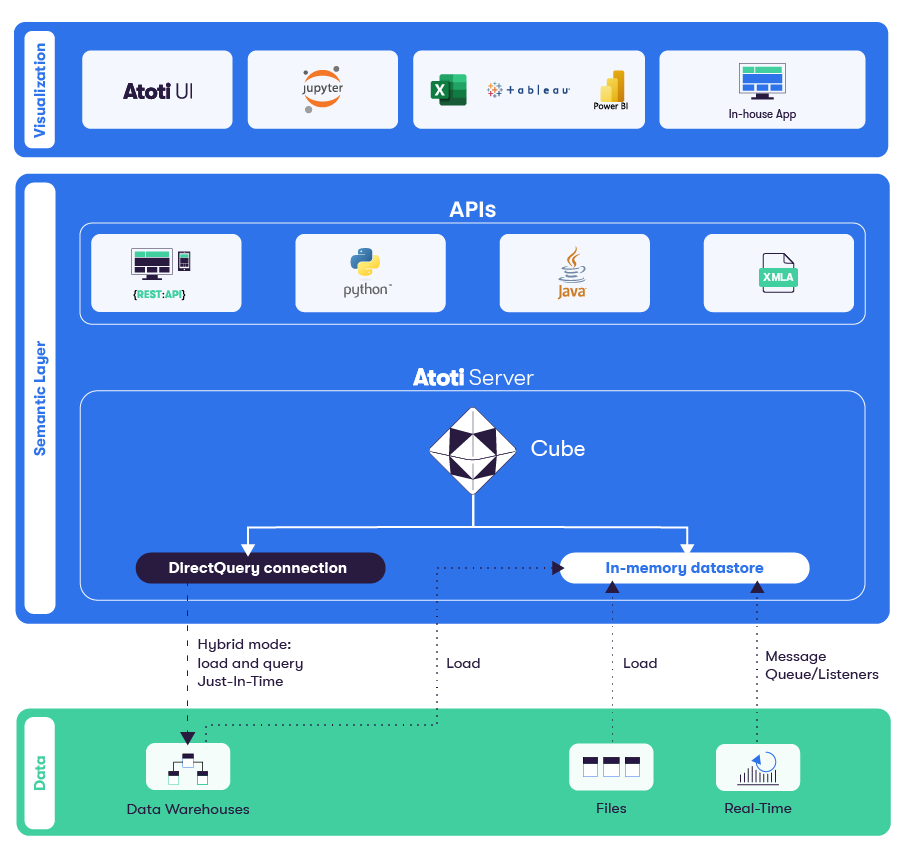
As an Atoti cube can work on top of a Datastore or an external database, a common interface is used to interact with such a component, check the Database API documentation.
Datastore
The datastore is Atoti In-Memory Column-Oriented Relational Database. It is designed to store data in order to perform analytical queries on this data.
An Atoti Datastore is:
- a relational database: it supports several tables (also called stores), with a star schema relationship between them.
- an in-memory database: to provide fast response times, at the expense of durability.
- it supports concurrent access, allowing more than one user to query and analyze data at one time.
To learn more about the Datastore, check the dedicated section in our documentation.
It is possible to load data into the datastore from several different sources: files, databases or message queues, check this section for more detail.
DirectQuery
Using DirectQuery, Atoti can perform the same analytics as the one on the datastore but on data stored in external data warehouses. The main benefit is a notable reduction of in-memory storage, which will in turn lead to a reduction in infrastructure costs.
DirectQuery is a suite of connectors to external data warehouses. Atoti cubes use these connectors to answer analytical queries with data from external databases, without storing the data in an in-memory datastore. DirectQuery connectors translate cube data requests to external database requests (mostly SQL).
In-memory computing is expensive while storage is cheap. For volumes of data that do not fit in-memory or that would be too expensive to store in-memory, DirectQuery enables analysis without being restricted to a subset of the data:
- Keep hot data in memory
- Keep cold data in the external database
Instead of keeping large volumes of data in memory, we leverage the scalability of the data warehouse for storage. This in turn reduces the need for memory on the Atoti server, and hence reduces infrastructure costs.
To learn more about DirectQuery, check the dedicated section in our documentation.
Datastore versus DirectQuery
Unlike Atoti data sources that load data into the datastore, we can only connect to a single database instance in an Atoti session through DirectQuery.
This is due to the data flow in an Atoti application.
Let's compare two scenarios in which the data is loaded from a SQL database. In the first scenario, the data is loaded into the datastore. In the second one the data would be accessed through DirectQuery.
For the datastore, it would be:
- Define the database schema
- Set up a datastore source connection with a data warehouse and load all the data into the datastore
- Define the cube
- Start the cube
- The cube will query the datastore at startup to fetch aggregates (hierarchies and aggregate providers, if any defined) and store the result
- Query the cube
- If the data is available in the cube, the cube will return it
- If not, the cube will query the datastore to serve the user query
In this scenario, queries are not performed on the data warehouse, except during datastore loading.
For DirectQuery it would be:
- Set up the DirectQuery connection and define your database schema
- Define the cube
- Start the cube
- The cube will query the data warehouse at startup to fetch aggregates (hierarchies and aggregate providers, if any defined) and store the result
- Query the cube
- If the data is available in the cube, the cube will return it
- If not, the cube will delegate to the DirectQuery connection to perform queries to the data warehouse.
In the second scenario, queries can be performed on the data warehouse at any time, and fewer data are loaded into memory at start-up.
Technical description
Datastore
An Atoti cube is always up-to-date with the data from the Datastore. It behaves as an aggregated materialized view on top of the datastore: it pre-computes in-memory aggregated data and holds also fact-level data in-memory. When a user submits an analytical query that can be performed solely on aggregated data thanks to the aggregated view, there will be no query to the datastore, allowing for a faster response. When the query needs to access data not present in the view, the query will be performed on the datastore.
DirectQuery
An Atoti cube with a DirectQuery connector takes a snapshot of the data from the external database. The cube data can be stale and mechanisms are provided to refresh it. It behaves as an aggregated materialized cache on top of a database: it loads in-memory aggregated data instead of fact-level data. When a user submits an analytical query that can be performed solely in-memory thanks to the aggregated cache, there will be no query to the external database, allowing for an instantaneous response. When the query needs to access data not present in the aggregate cache, the DirectQuery connector will forward the query to the external database, such queries should most of the time be drill-down with a reduced scope, allowing reasonable response time.
Datastore and DirectQuery
The DirectQuery connectors can also work in tandem with a datastore. With such a setup, the datastore is ideal to store either data that will be frequently queried or data that is frequently updated (also known as hot data). Other data can be kept in an external database and be accessed thanks to DirectQuery when needed.
This allows for faster response times, thanks to in-memory computing. While at the same time, reducing memory needs. Overall this will lead to improved infrastructure costs.
It is possible to mix the Datastore and DirectQuery in an Atoti application, either within the same cube or in different distributed cubes.
In the same cube, within the same schema, it is possible to have both in-memory tables and DirectQuery tables. A database query cannot join an in-memory table and external table, but it is possible to perform Copper joins. This is a good solution for a peripheral data table which is best stored in-memory because it changes very often, for instance a table containing currency conversion rates.
However, this setup does not allow the same table to be both in-memory and in DirectQuery. For example, very large datasets could be split into two tables with today's data and historical data respectively. This solution is possible with a distributed cube.
Thanks to Atoti's distribution feature, it is possible to have the same table both in-memory and in DirectQuery.
In a distributed setup, data from a table can be partitioned into two data cubes:
- one in-memory data cube for hot data
- one DirectQuery data cube for cold data (e.g. historical data)
For more details about splitting granular data between in-memory and DirectQuery read this page.