Indexing the Stores
What is an Index ?
An index allows better search performances. When a column is indexed, it allows knowing in which records a given value exists, without having to actually read all records in the column.
There are two types of indices based on their usage:
- Unique index: an index that allows to ensure uniqueness of a given value. Used for the key fields of a store.
- Secondary index: an index that allows repetition of the same value in different records. Used "only" for query performance.
Orthogonally to the unique/secondary nature of an index, there are two types of indices based on the structure of the data they represent:
- Single column index: an index based on the value of a single column in a store
- Composite index: an index based on the combination of values from several columns in a store
A unique index is automatically created over all the key fields of a store, allowing quick searching of a record by its key, and enforcing key uniqueness.
In some cases, queries might hit the datastore directly, for instance when using JUST_IN_TIME aggregates provider,
or when project code is written to directly query the stores.
In such cases, you may need to add indices on other columns or groups of columns to improve performance.
Key Fields Index
When a store is created with one key field, a unique, single column index is automatically created for that one field.
When a store is created with more than one key field, a unique, composite index that encompasses all these key fields is automatically created. The composite key ensures uniqueness in the index and in the store.
The following example shows a key comprising of three key fields.
StoreDescription.builder()
.withStoreName("Store")
.withField("ID_1")
.asKeyField()
.withField("ID_2")
.asKeyField()
.withField("ID_3")
.asKeyField()
As the unique key on this store is a combination of ID_1, ID_2, and ID_3, the composite index will only be used if all three are present in a query.
Indexing Individual Columns
If a single column is the key field of a store, it is automatically indexed. But one might also want to index an individual column, even if it is not a key field: indexing allows faster searches when a search is done directly on an indexed column.
The following example shows a field called "A", which isn't a key field but requires an index for faster searching.
StoreDescription.builder()
.withStoreName("Store")
.withField("ID")
.asKeyField()
.withField("A")
.indexed()
Contrary to the automatically created indices for key fields, the indices created with the indexed() method are
secondary indices (do not ensure uniqueness).
If a key field needs to be indexed (for example, there are two key fields so a composite index is created,
but one key field is often queried alone), it is also possible to use the indexed() method:
StoreDescription.builder()
.withStoreName("Store")
.withField("ID_1")
.asKeyField()
.withField("ID_2")
.indexed()
.asKeyField()
Composite Column Index
When a group of columns are frequently queried together, you can define an index that combines these columns using the
withIndexOn() method, as shown below.
StoreDescription.builder()
.withStoreName("Store")
.withField("ID")
.asKeyField()
.withField("A")
.withField("B")
.withField("C")
.withField("D")
.withIndexOn("A", "B", "C")
Queries that then specify all three values of A, B, and C will use this index.
Queries that only specify values A and C will not use this index, as a third value is required. If there are a lot of searches involving just A and C, it may be worth adding another composite index just for those two fields.
Logging Query Plans
When query performance needs to be investigated, you can set the server to log more detailed information as to what indices, if any, are being used.
The class com.qfs.store.query.impl.QueryCompiler can be (temporarily) set to the TRACE (logback)
or FINER (jul) logging level
to log such query plans.
The following sample log file output shows that a query has effectively done a table scan for the three columns:
Search on store Store, composed of:
Scan of field A
Scan of field B
Scan of field C
When analyzing typical usage, if such scans occur frequently, there is a good case to add a composite index on columns A, B, and C.
The output after adding such a composite index may then appear as follows, showing that the index is being used:
Secondary index lookup on (A, B, C)
Creating indices will incur a memory usage overhead, so as with traditional database design, they should only be added for the most commonly-executed queries.
Having too many indices could impact data loading times as there is also an overhead of maintaining those indices.
Automatic Indices
ActivePivot automatically creates a unique index containing all the key fields.
It will also create a composite secondary index on all fields used in a reference between two stores.
For example, if Store-1 references Store-2 through fields A, B, and C, then a secondary composite index using
A, B, and C is automatically created on Store-1.
A unique index on fields A, B, C will also be created for Store-2.
Consequently, when analyzing queries for scans and indices used, you may see that a secondary index lookup is being performed even if no explicit index for those fields has been created.
You can override this automatic index creation by calling dontIndexOwner() on the store reference builder.
Calling dontIndexOwner() will have several effects:
- It will reduce the memory footprint.
- It will speed up commits in the owner store.
- It will slow down the queries on those fields.
- It will slow down the propagation of updates from the target store to the owner store, and hence slow down the commit when committing in the target store.
We recommend that you keep the automatic indices, unless you encounter any issues with them.
Store Index Recommendation
We provide a utility that helps you create the necessary indices for your project, based on your actual usage when querying the stores.
This utility is available via MBeans, so you will need to access it via a tool which supports them, such as JConsole or jvisualvm for example. In the screenshots provided below, we use JConsole.
After launching your JConsole (or equivalent tool) and connecting to your application,
go to the MBeans tab and navigate to com.activeviam > Datastore > Datastore schema > Operations.
You will have access to the void enableStoreIndexRecommendation() operation.
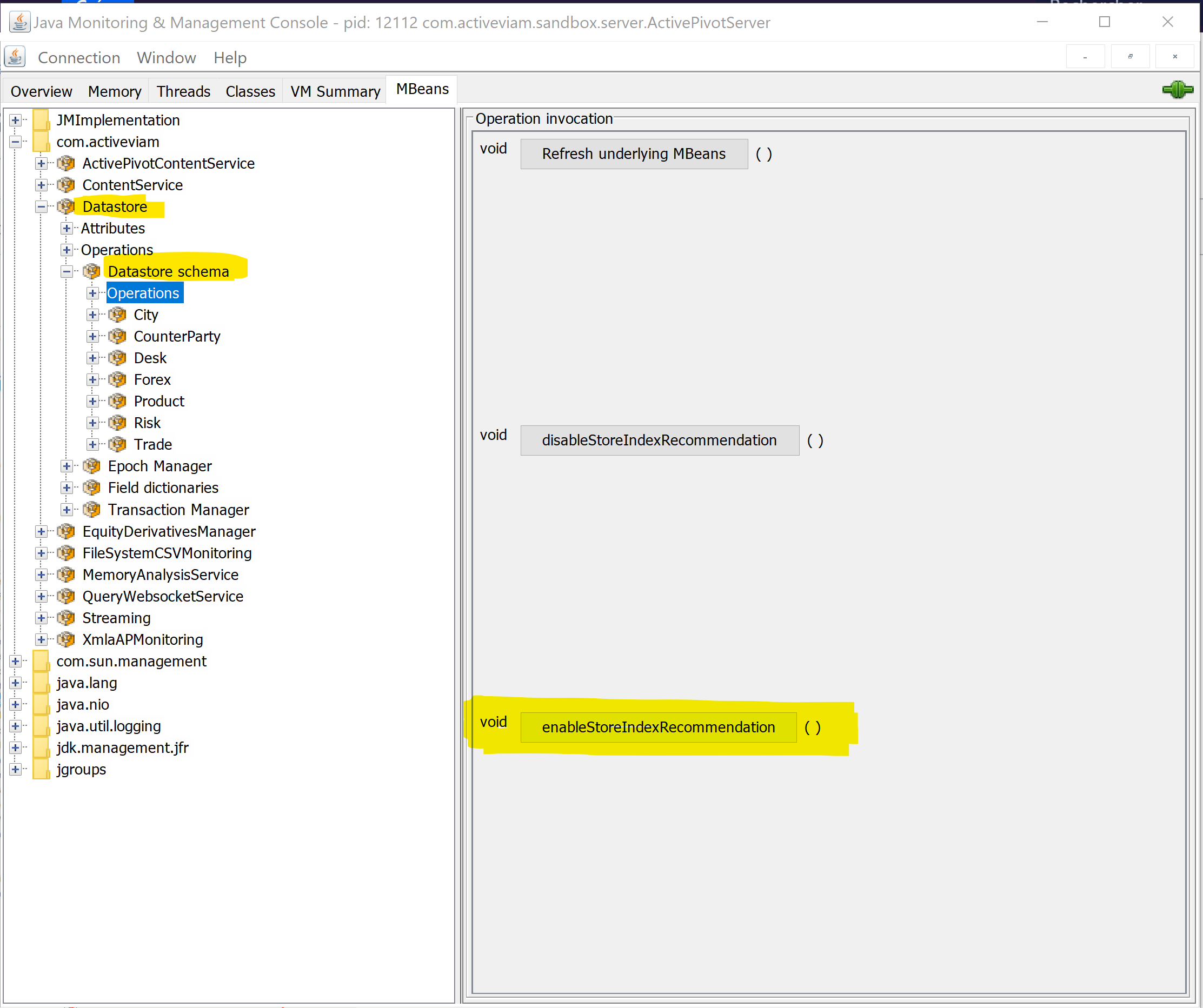
Launching this operation allows the datastore to register data about the queries it receives in order to provide you with index recommendations. When you click on the operation, you won't see anything happening at first, except that you receive a confirmation.
Now it's time for the magic to happen. Use the application with a typical workload of queries and operations (such as updateWhere). The datastore will register data about how each store is queried, and will be able to provide you with indexing recommendations for each store.
Navigate to each individual store in the Datastore schema MBean, and look for the IndexRecommendations attribute.
If the store index recommendation was not enabled, or if the workload you provided did not mandate using indices on that store,
you will only see an empty array.
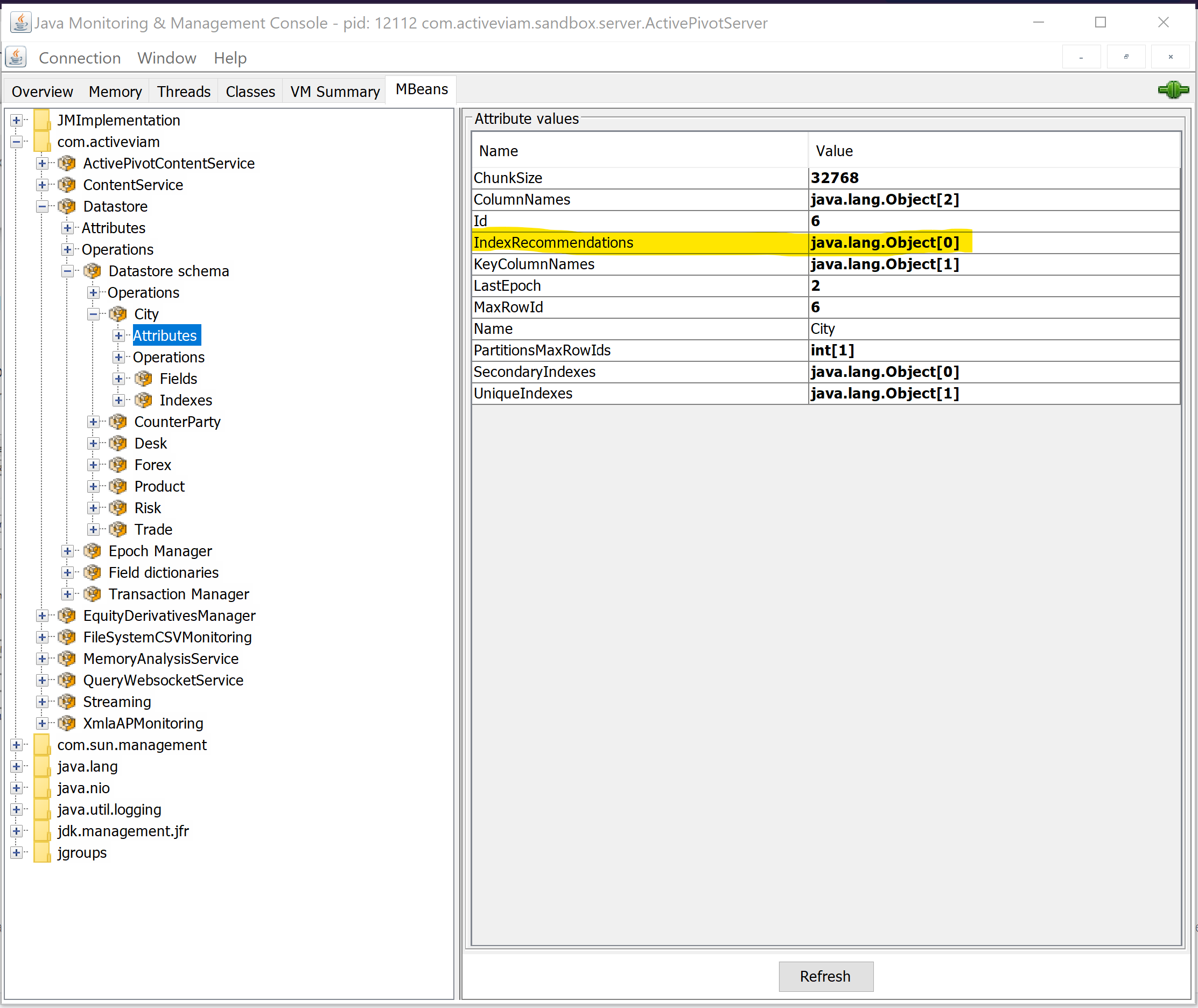
However, if there are some recommendations for indices on the store, based on the workload that happened since enabling the index recommendation feature, you will see a non-empty array and will be able to develop it by double-clicking on the value:

Note that each element of the array presents a field name and a number. The field name is the field on which we recommend creating an index, while the number represents the number of times an index on that field would have been useful for the queries that were inspected since enabling the index recommendation feature. Recommendations are ordered with that number descending, so that you can concentrate on the fields that are most frequently queried. The closer to real usage you get while providing the test workload, the more useful the recommendations !
These recommendations are based on the actual queries that hit each individual store. Thus, only queries that are directly made to the datastore or aggregates / MDX queries that hit the JIT (Just In Time) Aggregates Provider are taken into account.