Content Server
ContentServer is a relatively technical, secondary, component rather than a first-class member of the ActiveViam product family, but it is nonetheless a required component.
It essentially implements a generic key/value storage for various metadata used by the ActiveViam products (e.g. calculated measures / KPIs for ActivePivot, bookmarks / application settings for Atoti UI). It supports persistence and auditing of the metadata.
Architecture
ContentServer provides a way for ActivePivot (or other components) to remotely store data in a way similar to a file system. Data are organized into directories that can contain files or other directories. Each file or directory has associated permissions that grant read or write access to given roles. From now on, we will consider directories to be simply a particular kind of file.
Before diving into deeper considerations, a distinction must be made between "content service" and ContentServer.
- A content service (interface
IContentService) is a component that actually takes care of storing and retrieving the data. This component runs within the scope of the JVM and does not expose its methods to the outside world by itself. - ContentServer is a standalone server component that hosts a content service and allows for remote access to it.
The only implementation of ContentServer for now is the
RestContentServerthat exposes a REST API, allowing a user to access the underlying content service. - The ActivePivot Content Service (interface
IActivePivotContentService) is a convenience wrapper around the generic content service contract, with methods specialized for dealing with ActivePivot metadata.
The following schema exposes the standard way of setting up ContentServer in production. One can obviously use the same approach for testing environment or dev, though usually dev - at least - will use a lighter approach.
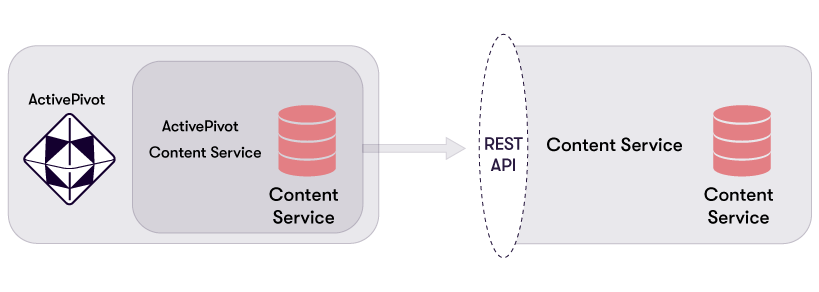
- On the right, ContentServer holds data into a content service and exposes them via a REST API.
- On the left, ActivePivot has its own specialized implementation of a content service, which wraps around a generic implementation of content service that simply delegate all requests (initiated locally) to the remote content service hosted in ContentServer.
For the sake of development environments, ActivePivot can (and by default will) start with a so-called "local" content service.
This means that as a developer you do not need to run ContentServer in a separate JVM to test your application.
Configuration
Various implementations
There are several implementations of a content service that can be chosen from.
- The
InMemoryContentServicedoes not persist its content: it will lose everything when the server is stopped. - The
HibernateContentServicerelies on Hibernate to store and persist its content in a database.
It does not keep track of the changes made to the content, and only remembers the last editor and the last edit time. - The
AuditableHibernateContentServiceadds audit trail capabilities. It has several methods that help a user audit the data, likegetHistoryAfterthat retrieves all modifications done to all entries at the given path after the given date. Note that when using the auditable content service, deleting an entry does not mean that it is actually removed from the database: the audit history will just show that the bookmark has become obsolete, and is no longer available to users.
TheAuditableHibernateContentServiceAPI allows to actually remove obsolete entries from the database through methodsremoveEntriesBeforeandremoveObsoleteEntries. This content service is the one available by default in the sandbox, both in the ActivePivot sandbox with a "local" content server (seeEmbeddedContentServiceConfigimported inActivePivotServerConfig), and the standalone ContentServer sandbox (seeContentServiceConfigimported inContentServerConfig). - The remote content service relies on a remote REST-enabled ContentServer to store its data,
and delegates all of its calls to the content service that is hosted there.
As such its behavior depends on which type of content service has been set up on the ContentServer: it may or may not persist the data, and may or may not have an audit trail, depending on the chosen implementation. This is the implementation used by the ActivePivot sandbox when using a remote content service (seeRemoteContentServiceConfigimported inActivePivotServerConfig).
How to Configure?
Your Spring configuration must create an IActivePivotContentService bean which relies on one of the four implementations.
You can use the ActivePivotContentServiceBuilder.
For instance, the simplest configuration using an in-memory content service (no persistence, no audit, no delegation to a remote ContentServer):
@Bean
public IActivePivotContentService activePivotContentService() {
return new ActivePivotContentServiceBuilder()
.withoutPersistence()
.withoutCache()
.needInitialization("ROLE_USER", "ROLE_USER")
.build();
}
More realistic (for test and prod usage) configurations are showcased in the ActivePivot Sandbox,
as mentioned in the previous section.
The sandbox also shows how to expose the JMX beans of the content service, and how to expose a "local"
(i.e. hosted in the ActivePivot web application) ContentServer REST API at a given URL.
Configuration of the database for Hibernate Content Service
As of now there are no Content Service implementations available to communicate with external
databases other than HibernateContentService and AuditableHibernateContentService.
These implementations delegate all communication with databases to Hibernate and thus
allow pretty much the same database configuration / management customizations as any arbitrary
Hibernate application.
In order to mount Hibernate Content Service, one needs a file called
contentservice.db.properties.
The Content Service sandbox provides an example of such file.
This example contains several properties prefixed by content-service.db.hibernate.
These are ordinary Hibernate properties that bypass the ActivePivot codebase.
Internally each of these properties will be passed to Hibernate configuration classes
"as they are", with contentservice.db prefix omitted.
In this documentation we will discuss only a few important configuration properties.
The full documentation of Hibernate is available
here.
All the available properties are listed in this
section.
They all may be used with Hibernate implementations of the Content Service,
if prefixed by contentservice.db.
We encourage users to refer to full documentation for any missing details.
content-service.db.hibernate.dialectdefines an SQL dialect to be used for database communications. This choice depends on the type of database you are using. In the sandbox example theH2database is used.content-service.db.driverClassNameassigns the driver class for database communications. In the example we need it to point toorg.h2.Driverbecause we've chosen H2 database. This property and the dialect should always be modified together.content-service.db.hibernate.hbm2ddl.autodefines what the Hibernate app should really do with the database. Automatically validates or exports schema DDL to the database when the SessionFactory is created. The available options arevalidate,update,createandcreate-drop. Withcreate-drop, the database schema will be dropped when the SessionFactory is closed explicitly.content-service.db.hibernate.show_sqldefines whether the SQL commands that Hibernate performs will be printed to the user.
As for any Hibernate application, it is possible to create / manage the SQL database manually and connect the Hibernate service to an already prepared database. The easiest and most robust way to get the exact SQL commands to create an appropriate database manually is yet again to use Hibernate features, because of varying SQL dialects. For example, one may define
content-service.db.hibernate.hbm2ddl.auto=create
content-service.db.hibernate.show_sql=true
and Hibernate will show the exact SQL commands written in an appropriate SQL dialect. Then these commands may be extended and modified by the user without any further Java code interactions.
There are a few facts about Content Server databases that may be useful during configuration:
- The optimal initial size of the required storage is very dependent on your use case, but we saw very few clients requiring more than 1GB of memory in total.
- The growth of the database will be directly related to the number of users (settings that need to be saved) and the number of dashboards/folders.
- The typical workload is a lot of reads and only a few writes (i.e. when users need to save something).
- For
HibernateContentServiceeach user action has a direct impact on the underlying database. If the user removes bookmarks or filters the data will be automatically cleared from the database. ForAuditableHibernateContentServicethe data is not cleared automatically. You may trigger the removal by calling methodsremoveObsoleteEntries()orremoveEntriesBefore(Date)ofAuditableHibernateContentServiceclass, but these operations shouldn't be called too often in order to not affect the performance. There are no other housekeeping actions done by the Content Server. - In ActivePivot we do not use any of the Spring Data JPA features yet.
Sharing one ContentServer between multiple ActivePivot Instances
There are different use cases possible here... For instance (typically, but not exhaustively):
- When using a distributed architecture to deploy ActivePivot.
- When deploying multiple projects (one customized ActivePivot for each) but wanting a single Atoti UI to browse all relevant bookmarks from one place. There are two sub-cases to consider here: -- Multiple instances of ActivePivot sharing the same data model / cubes (you can look at that in terms of description of the ActivePivot Manager within the ActivePivot instance). -- Multiple instances of ActivePivot using different data models...
In the later case, one needs to make sure there is no conflict when storing the associated metadata in ContentServer. That is, if you have two different types of ActivePivot to deal with (two different data model descriptions) then you want two sets of ActivePivot metadata to coexist in ContentServer, each in different "directories". And then, you need the respective ActivePivot instances to know where (in terms of directory) to look for the metadata.
This can be achieved by assigning a prefix to each type of ActivePivot instance. Note that by default, the prefix is "pivot". That is the name of the directory under which you would normally find ActivePivot metadata in ContentServer if you have done nothing special (explicit) with configuring a prefix when defining the content service you use on ActivePivot side.
Here below is an example on how to define a specific prefix:
@Bean
public IActivePivotContentService activePivotContentService() {
return new ActivePivotContentServiceBuilder()
.withPrefix("myActivePivotTypeA")
.withoutPersistence()
.withoutCache()
.needInitialization("ROLE_USER", "ROLE_USER")
.build();
}
Initialization / Setup Workflow
The purpose of this section is to describe how one should set up (and then use) a content service (whether it's a "local" one embedded in ActivePivot, or a remote one hosted in ContentServer).
The first time you want to use content service with a particular type of ActivePivot (i.e. a particular project, with specific data model, AP manager description, etc. Refer to previous section) you will need to ensure that the directory to receive the metadata for that ActivePivot has been properly created (including read/write access rights) and also (often) you may want to preload some metadata (e.g. predefined calculated measures, etc.).
So, for a first start, the steps are:
- Launch ContentServer
- Initialize ContentServer (
ActivePivotContentServiceUtilis there to help you) - Launch ActivePivot
In the sandbox, you can see examples on how to initialize the ContentServer:
- in
EmbeddedContentServiceConfig, we use theActivePivotContentServiceBuilderwith itsneedInitializationmethod (which callsActivePivotContentServiceUtil.initializefor you). - in
RemoteContentServiceConfig, we directly callActivePivotContentServiceUtil.initializein theinitializeIfNeededmethod.
Note that in both cases the Spring wiring order ensure that the initialization of the ContentServer is done before starting the ActivePivot.
Once the content service has been properly initialized for the metadata of a particular type of ActivePivot, you can start instances of such ActivePivot type without re-running the content service setup (unless, of course, you want to re-run some of it, such as reloading some metadata that have changed).
Security
Each file in ContentServer has associated permissions:
- The owner is the role for which users have read/write access to the file.
- The reader is the role for which users have read-only access to the file.
- If one does not belong to either the reader or owner role, one does not have any access to the file.
The exact permissions follow these rules:
Each file or directory has an owner group and a reader group, and... --The permissions will be written like this:
owner:reader. -- The users who belong to the owner group will be called owners. -- The users who belong to the reader group will be called readers.To list all the files within a directory, one needs to belong to the reader group of it.
A user can always list all the files he has access to under any given directory, independently of the depth at which these files are.
If a user has access to a file, he is allowed to know that its parent directory exists. Without read access to its parents, it cannot however know more than the mere fact that it exists, and he cannot know who the readers are.
To create a file inside a directory, one needs to belong to its owner group.
To edit or delete a file, one needs to belong to its owner group.
To read the content of a file, one needs to belong to the file’s owner or reader group.
To delete a directory, one needs to belong to the owner of this directory and all of its files.
The reader group may be empty/null.
There is also a special “root” group and any of the members of this group have the sames privileges as the owners.
Initial folder (the
/directory) has the following permissionroot:null.To edit the permissions of a file, a user needs to be an owner or a root user. A standard user cannot change the owner/reader group of a file to a group that she isn’t part of, only a root user can do this.
Admin UI
A user interface to browse the content in the ContentServer and the datastore is available (if configured as such) wherever the ContentServer API has been exposed/deployed.
For example, in the ActivePivot Sandbox, the Admin UI is exposed at <root URL>/content,
where <root URL> = <host>:<port>/<application path> of either ActivePivot (if using an "embedded ContentServer"
approach) or ContentServer (if using a "remote ContentServer" approach).
The Admin UI allows one to see all the content one has access to (a.k.a. specifically,
given the access rights one has been granted).
One will be able to see the content of the file if and only if one has read access to it,
and to modify its permissions and content, if and only if one has write access to it.
In the following example we see how the Admin UI allows a super-user to read the permissions on branches.
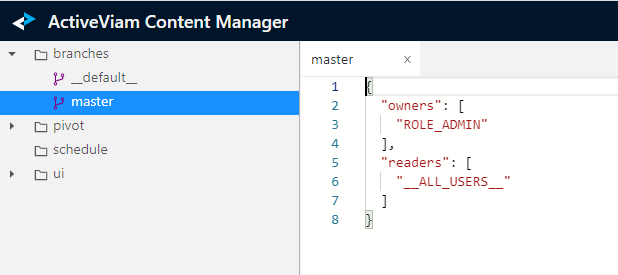
Entitlements in the Content Server
ActivePivot entitlements are stored as context values in the ContentServer. ContextValues that are modified through the ActivePivot ContentService are immediately available to the ActivePivot. However, context values that are edited directly in the ContentServer are ignored by a running ActivePivot, because the context values of the ActivePivot are cached. There are solutions to overcome that :
- You can set a time to live for the cache
- You can reset the cache using the provided "Clear cache" JMX Operation
Import and Export
It is possible to perform imports in ContentServer using the REST API or the ContentServiceSnapshotter.
In the case of ContentServer with persistence in a database, the import speed greatly depends on the network speed
between the machine hosting ContentServer and the database, and on the database performance itself.
For example if the content is persisted in an Azure database, the import speed will be optimized if ContentServer
is hosted in an Azure VM and if the number of DTUs of the database is temporarily augmented for the time of the import.
An import parameter for the POST method of the REST API allows to import a whole content subtree
in a single bulk operation, which significantly improves performance - it is used in the ContentServiceSnapshotter
in the case of a remote content service.
The export is simply the GET method of the REST API.