> ## Documentation Index
> Fetch the complete documentation index at: https://docs.activeviam.com/llms.txt
> Use this file to discover all available pages before exploring further.
# Split granular data between in-memory datastore and DirectQuery database
Deploying a 100% DirectQuery application is a valid use case, however often it can be a good idea to put part of the granular data in-memory.
This page explains when and how.
## Hybrid distributed mode
A classic use case for DirectQuery is giving access to the historical data of an in-memory Atoti application.
Historical data may be too large to fit entirely in-memory or too costly for “cold” data that users rarely access.
For that, it is possible to have Atoti DirectQuery nodes alongside Atoti in-memory nodes in a Distributed set-up and expose it in a unified and consistent data model to the end users.
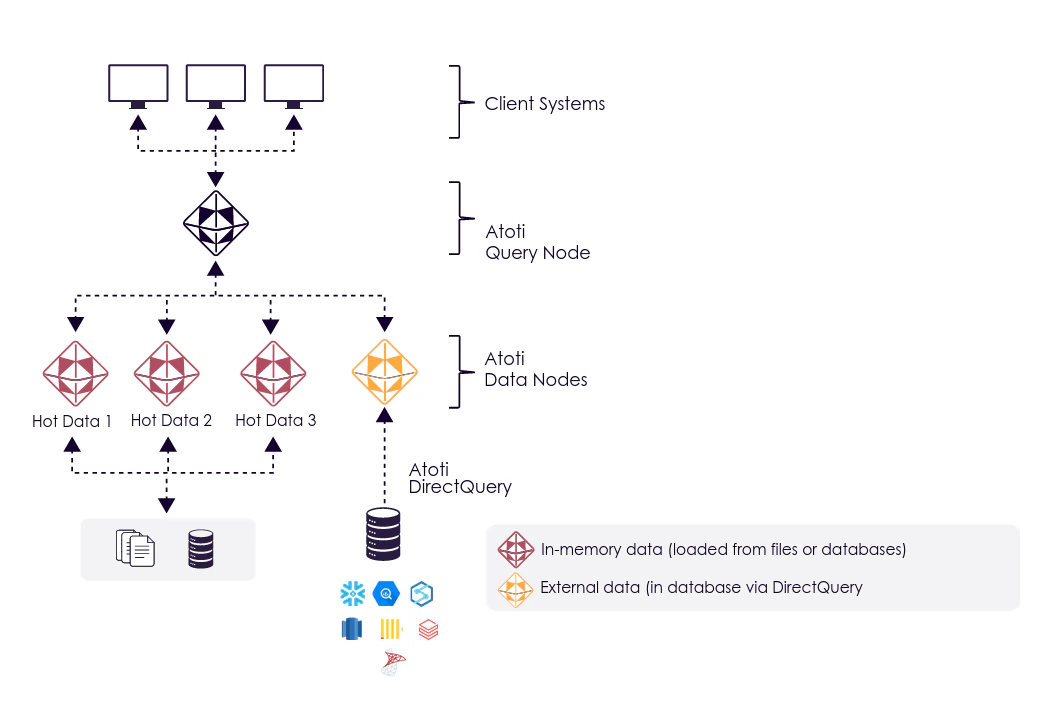 Note that you don't have to redefine your entire project to add a DirectQuery node: As DirectQuery connectors and the Datastore are abstracted behind the `IDatabase` interface, the same cube definitions (measures, hierarchies...) can be used for all the nodes.
A usual set-up to split "hot" and "cold" data is to use a date hierarchy:
* the recent dates are put in-memory because they will receive a lot of queries and might have frequent real-time updates.
* the older dates are put in an external data warehouse and accessed via DirectQuery because it accessed less frequently and receive rare updates. Part of this data can be pre-aggregated to provide an historical overview pretty quickly.
Note that you don't have to redefine your entire project to add a DirectQuery node: As DirectQuery connectors and the Datastore are abstracted behind the `IDatabase` interface, the same cube definitions (measures, hierarchies...) can be used for all the nodes.
A usual set-up to split "hot" and "cold" data is to use a date hierarchy:
* the recent dates are put in-memory because they will receive a lot of queries and might have frequent real-time updates.
* the older dates are put in an external data warehouse and accessed via DirectQuery because it accessed less frequently and receive rare updates. Part of this data can be pre-aggregated to provide an historical overview pretty quickly.
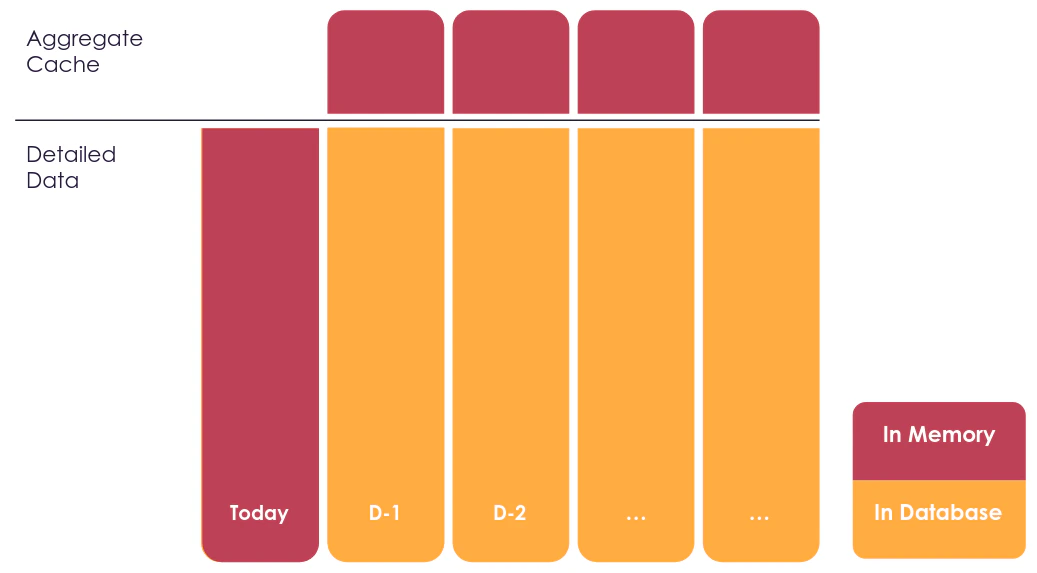 These parts of the data will be stored in different places:
These parts of the data will be stored in different places:
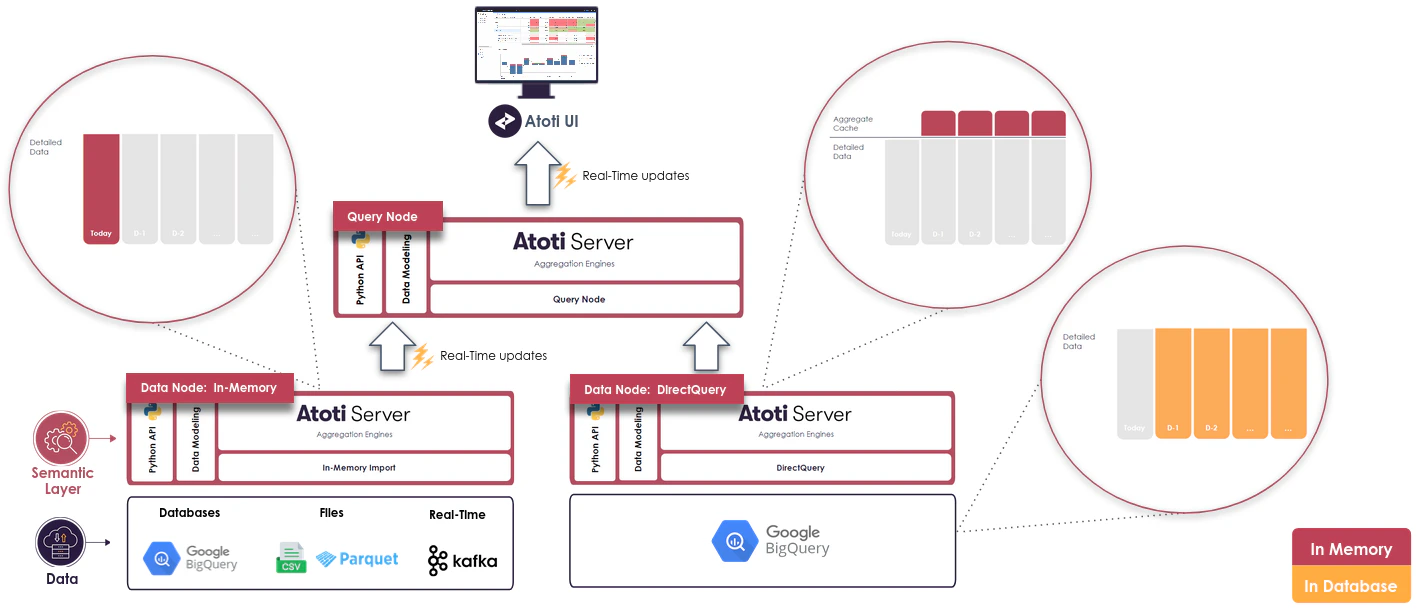 With such a setup, the size of the in-memory data can stay reasonably small as most of the data stays in the external database. Moreover, queries will be fast enough for interactive analysis:
* The majority of queries will be on recent dates and hit the in-memory nodes
* Historical trends queries will hit the DirectQuery partial aggregate providers which are in-memory
* When users start to drill down on historical data, the queries will be sent to the external database but at this point there should be a scope filtered enough (1 book on 1 date for instance) for the warehouse to answer quickly.
With such a setup, the size of the in-memory data can stay reasonably small as most of the data stays in the external database. Moreover, queries will be fast enough for interactive analysis:
* The majority of queries will be on recent dates and hit the in-memory nodes
* Historical trends queries will hit the DirectQuery partial aggregate providers which are in-memory
* When users start to drill down on historical data, the queries will be sent to the external database but at this point there should be a scope filtered enough (1 book on 1 date for instance) for the warehouse to answer quickly.